UGFydCA0IG9mIFRoaW5raW5nIFNlcnZlcmxlc3Mg4oCU4oCKIEFkZHJlc3NpbmcgU2VjdXJpdHkg SXNzdWVz

This is a guest repost by Ken Fromm, a 3x tech co-founder — Vivid Studios, Loomia, and Iron.io. Here's Part 1 and 2 and 3.
This post is the last of a four-part series of that will dive into developing applications in a serverless way. These insights are derived from several years working with hundreds of developers while they built and operated serverless applications and functions.
The platform was the serverless platform from Iron.io but these lessons can also apply to AWS Lambda, Google Cloud Functions, Azure Functions, and IBM’s OpenWhisk project.
Arriving at a good definition of cloud IT security is difficult especially in the context of highly scalable distributed systems like those found in serverless platforms. The purpose of this post is to not to provide an exhaustive set of principles but instead highlight areas that developers, architects, and security officers might wish to consider when evaluating or setting up serverless platforms.
Serverless Processing — Similar But Different
High-scale task processing is certainly not a new concept in IT as it has parallels that date back to the days of job processing on mainframes. The abstraction layer provided by serverless process — in combination with large-scale cloud infrastructure and advanced container technologies — does, however, bring about capabilities that are markedly different than even just a few years ago.
By plugging into an serverless computing platforms, developers do not need to provision resources based on current or anticipated loads or put great effort into planning for new projects. Working and thinking at the task level means that developers are not paying for resources they are not using. Also, regardless of the number of projects in production or in development, developers using serverless processing do not have to worry about managing resources or provisioning systems.
Iron.io
Most questionnaires still viewed servers as persistent entities needing constant care and feeding. They presumed physical resources as opposed to virtualization, autoscaling, shared resources, and separation of concerns. Their questions lack differentiation between data centers and development and operation centers. A few still asked for the ability to physically inspect data centers which is, by and large, not really an option these days. And very few addressed APIs, logging, data persistence, or data retention.
The format of the sections below follows the order found in many of these security questionnaires as well as several cloud security policies. The order has been flipped a bit to start with areas where developers can have an impact. Later sections will address platform and system issues which teams will want to be aware of but are largely in the domain of serverless platforms and infrastructure providers.
Security Topics
Data Security
Data security is one area where developers can take steps to augment existing security measures serverless platforms might have in place. A first concern should be to make sure data payloads are secure not just in transit but also at rest. Because there can be many independent workloads and processes in place and because processing can take place across a large number of cores — and potentially regions and even clouds — it is important to treat each task payload as a separate entity with separate exposure and threat vectors.
Yes, SSL should be used when transmitting data, virtual private networks can and should be deployed, and data storage components can offer encryption capabilities but even with these measures, task payloads can and will be replicated and persisted in a number of places. Payloads may be placed on message queues, for example, or included as part of audit trails.
And even after a payload is processed, it may persist in the system for a longer period of time as a deleted/archived record but not fully erased. How long a processed workload might persist in a system depends on the platform’s data retention and backup policies.
Data Encryption
The potential exposure of task payloads means that developers should make sure that task payloads are encrypted separate from any network encryption. At run-time, the task can decrypt the payload as an initial step in the processing.
Some serverless platforms may encrypt task payloads as a normal course of operation but you will want to verify with the platform in question. Even with platform-level encryption, you may want to encrypt task payloads on your own as an added measure as any system decryption keys will be out of your hands and therefore at risk for compromise by internal or external parties.
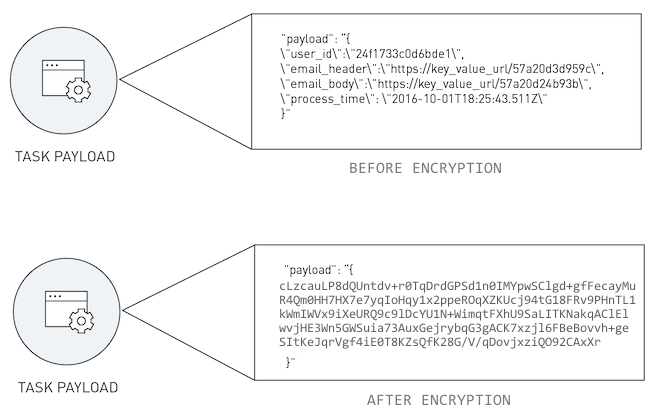
Encrypting Task Payloads
A couple considerations to point out here:
- Providing a key for tasks to use to decrypt data does take conscious thought. Given tasks are largely stateless and ephemeral, the only form of data available for tasks to use comes from task payloads, data calls, or config data — the access to which is provided by the serverless platform. Given storing the key in the task payload is not an option and data calls are expensive and impractical for this use case, the only real way to provide a decrypt key is via the config data. Storing the key as part of the platform config data does mean the key is available and partially exposed within your system. Some platforms do allow for both global and local config data which means in the case of the latter, access would only be for the particular class of task or function.
- There have been some recent changes in Docker container security which could open up avenues for either injecting keys into containers or for sharing between containers. This can be helpful especially in situations where task containers are not broken down after execution but instead persist and process a continual stream of payloads. (Note that serverless platforms will be likely be the ones to make use of these capabilities as as opposed to end-users.)
- Encrypting payloads on the client-side will make introspection of tasks more difficult. A number of the serverless platforms offer dashboards that allow introspection of individual tasks including display of the task payloads. Encrypting payloads can make this capability less useful and debugging errors in tasks harder.
Data Partitioning
Another way to ensure safe payload handling when processing jobs in the cloud is to take advantage of data partitioning strategies. Data partitioning refers to separating elements of a data object and only providing a task with the elements needed for that task to process. In the email example described in Part 1 of this series, data partitioning means sending only the object or objects needed by a task and not the entire email message. In this way, task payloads cannot expose what they do not have.
Partitioning Data
Data Anonymization
Similarly, data anonymization is a way of sanitizing information by either removing or obscuring certain elements of the data so as to protect personally identifiable information.
[1]
Data anonymization is often used as a way to transfer and share data between entities such as two different companies or agencies. In the context of medical data, it can refer to data from a patient not being able to identify the patient. Within a task processing environment, keys can be used in replacement of the sensitive data and then the results de-anonymized by cross-referencing the keys with other data to re-identify and re-associate the processed data.
Anonymizing Sensitive IDs in Task Payloads
A Note on Adding in Security Measures
Security often seems to be an afterthought — addressed after getting things running and into production. It is better though to put basic measures in place sooner in the process rather than later.
Adding in security measures as part of a secondary release can easily cross into several components or layers of the architecture which only magnifies the time and cost to do it later. It is also not uncommon for outwardly-facing features to take priority over internal fixes.
For example, encrypting, partitioning, or anonymizing data after the fact introduces a ton of additional complexity and brings with it the need to perform a full set of comprehensive tests. This work wouldn’t be needed if data protection was added in at the start.
Task Security
Container Isolation/Security
Because tasks can be running in shared/public servers, it is critical that serverless platforms maintain strict isolation between tasks. Fortunately, container technologies provide such a mechanism. Serverless platforms that make proper use of containers can make it so tasks run within their own isolated environments and are unable to interact with other tasks or areas of the system. Each task container is able to isolate processes, memory, and the file system. Additionally, host-based firewalls can add additional restrictions to prevent applications from establishing local and inbound network connections.
Note though that despite strict isolation there still is the potential for disruption via a noisy neighbor issue. Despite running as separate entities, tasks running on a server can collide for resources thereby creating blocks and/or limitations. For example, while the stated memory limit for a task may be a set size, the combination of limits may exceed the total resource limit for the server — that is if the all the tasks max out their memory and the system limit is less than the sum of the tasks. This situation could result in a task failure which might be hard to debug as it might show memory error but pertain to a server limit as opposed to a task limit.
Containers Isolate System Resources for Tasks
Concurrency Limits, Monitoring, and Alerts
Another area that developers can take measures to create a more secure processing environment is to apply reasonable limits on the task parameters wherever possible. The primary limit to address is concurrency but other limits such as memory or task duration can also apply. In the case where demand for a service or function is highly scalable, concurrency limits may not be practical. In cases where demand is within a narrower range, however, projects can benefit by using concurrency as a governor against unintended actions.
Note that even under throttled conditions, a large amount of tasks can still be processed. Applying practical concurrency limits, however, can allow for alerts and monitoring measures to kick in to catch unintended or malicious activity.
If alerting capabilities exist within a serverless platform then putting in alerts for queue sizes, concurrency, or wait times can make a lot of sense. For platforms that lack alerting capabilities, consider making use of real-time logging services to set up relevant triggers and notifications. Highly concurrent processing does bring with it the risk of out-of-control processing scenarios. Putting in restrictions and monitoring to address them makes both good business and engineering sense.
Code Security
A related item with task security is code security. Ideally, serverless platforms will encrypt the code that is stored in a system and decode it at run time. If the code is stored as a container and the container is encrypted by the platform, then the issue should largely be taken care of. As with difficulties inspecting encrypted payloads, inspecting encrypted code via a dashboard may pose interface challenges for a serverless platform.
Additionally, it makes sense to add in code and image scanning as part of the process of uploading tasks into a serverless platform. Even though tasks and functions tend to be smaller and easier to manually inspect, third-party code packages can contain malicious code. Creating scripts or putting in place an automated system to scan and verify code is good way to gain additional peace of mind.
System Security
System Verification and Updates
With serverless architectures, many system-level security measures take place prior to run-time. Because tasks in a serverless platform are not meant to run on an infinite duration, servers are viewed as largely disposable. In other words, instead of running a virus scan or applying runtime patches to production servers, servers can be simply be removed from the distribution list that job controllers use to route tasks. After all tasks have completed processing on these servers, the servers are terminated and other servers launched and placed within the rotation as replacements.
As a result, serverless platforms will often include image/container verification and virus scanning as part of the development and deployment stages of their ops cycle and will recycle them on a regular schedule. This is different from past behaviors where performing checks, tests, and updates on production systems is more standard. One advantage is that by limiting both access and changes to production systems, ops teams can reduce the attack vectors that are possible on production servers.
Since base Docker images and other container images can have vulnerabilities, it is important for the serverless platforms themselves to know about these and address them. Docker recommends the use of animage scanner. Likewise CoreOS has a similar project.
Lifecycle for a Task Processing Server
System Throttling, Access Controls, and Workflow Management
The concept of limiting concurrency and other task resources is mentioned in a previous section. When it comes to managing large-scale distributed workflows, though, this step is only a basic on. It is somewhat brittle as teams have to be aware of the limits and increase them when loads increase.
To properly manage serverless workflows, a higher-level approach is needed that acts as an overlay over all calls and invocations in a system — not just calls for task processing. In other words, processing a single task is one element in what could be a series of task invoccations, message queue calls, cache hits, database accesses, and external http requests.
Gaining insight to these calls and managing them means addressing it via a layer above the processing platform. As we are in somewhat early in this serverless cycle, no clear approach has surfaced on how to provide this global control layer. Given the interest and growth rate in serverless computing, however, I expect there to be solid movement in this area in the near and mid-term.
Network Security
API Gateways
API gateways provide a uniformed and constrained method of service access with strict authentication — OAuth or JWT, for example. API gateways also typically offer sophisticated monitoring and alerting capabilities. They are critical components in reducing security threats and enabling improved monitoring of system activity.
A recommendation here is to make use of private API endpoints if they are available. This move can help mitigate the effects of a DDOS attacks on publicly available API endpoints.
Dereferenced URls and/or direct IP addresses can address DDOS attacks on nameservers although this is a more advanced topic to address with a platform’s security experts.
Proper Use of APIs are Critical within a Distributed Processing Workflow
Virtual Private Networks
Virtual private networks are another measure to increase network security. VPNs can be set up and provisioned much more easily than physical networks and firewalls. Most cloud infrastructures will provide these capabilities which, in turn, means serverless platforms can inherit them and offer them as additional features to their customers.
VPNs in the context of serverless processing are worth any initial upfront effort to employ. Using a VPN is another measure that is easier to do at the start then to try and add it in later.
Penetration Testing
In terms of penetration testing, the use of APIs as well as highly limited access to internal components makes this issue an easier one to address on one level — fewer access targets in combination with more limited access methods.
On the other hand, the distributed topology and componentry involved in a serverless architecture as well as the large number of server makes it important that these servers and components have strict conformity regarding internal access methods and are not available in any public form.
Fortunately, most network security measures, aside from making use of private API endpoints and VPNs where available, will be the domain of the serverless platform and/or the underlying infrastructure provider.
Physical Security
Most security questionnaires will often address physical security as a one-size-fits-all proposition. It goes without saying, however, that production data centers should be considered differently than development offices or business operation centers. Gaining unauthorized access into a business office is a serious matter but comprising a data center running production workloads is on a completely different scale.
Data centers running production and development workloads, for example, are not likely to provide inspection capabilities except in the most severe circumstances. Development and operations centers may not store data onsite. Questions and concerns should therefore be tailored so as to separate workload processing and data management of production loads (i.e. your workloads and your data) from development efforts and business operations.
As part of this understanding, you will want to understand the full topology of the platform — where code and data components are stored and processed, how logging is handled, and any downstream providers that may be involved. Fortunately, most serverless platforms will use reputable cloud infrastructures which will, by and large, have sophisticated physical security measures in place thereby allowing them to inherit these measures.
Datacenters, Development Offices, and Business Ops Centers
Summary
Making use of a serverless approaches is not only a tactical tool for resource optimization but also a strategic necessity that can be directly applied to increase organizational speed and agility. Going serverless lets developers shift their focus from the server level to the task level. It lets them focus on the features and capabilities of their applications and systems instead of managing the complexity of the backend infrastructure.
Despite the title of this series, there are often less things to think about when moving to a serverless architecture. Writing code, uploading it, and seeing it run out-the-gate at high concurrency never gets old. This agility translates into faster cycles for creating things and releasing them into production. Things do get more complicated when you bring in task issues, workflows, data issues, and security but some simple foresight, steady guidelines, and solid architectural principles will make these seem as second nature.
Back in 2012, I made a call back that the future of computing will be serverless. Here in 2017, that view has become even more clear.



