How ipdata serves 25M API calls from 10 infinitely scalable global endpoints for $150 a month


This is a guest post by Jonathan Kosgei, founder of ipdata, an IP Geolocation API.
I woke up on Black Friday last year to a barrage of emails from users reporting 503 errors from the ipdata API.
Our users typically call our API on each page request on their websites to geolocate their users and localize their content. So this particular failure was directly impacting our users’ websites on the biggest sales day of the year.
I only lost one user that day but I came close to losing many more.
This sequence of events and their inexplicable nature — cpu, mem and i/o were nowhere near capacity. As well as concerns on how well (if at all) we would scale, given our outage, were a big wake up call to rethink our existing infrastructure.
Our Tech stack at the time
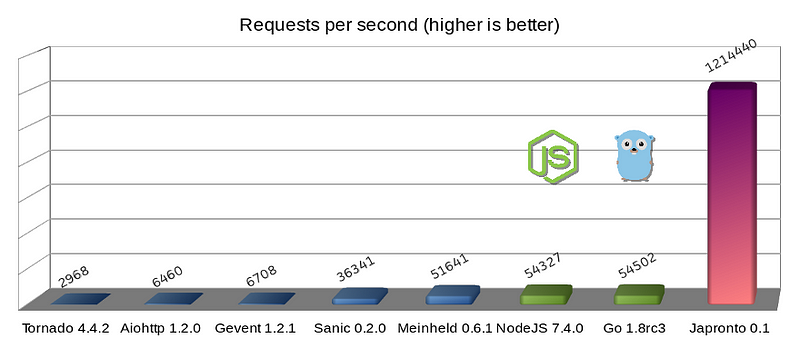
- Japronto Python Framework
- Redis
- AWS EC2 nodes
- AWS Elastic Loadbalancers
- Route53 Latency Based Routing
I had run tests on several new, promising Python micro-frameworks.
Choosing between `aiohttp`, `sanic` and `japronto` I settled on Japronto after benchmarking the 3 using https://github.com/samuelcolvin/aiohttp-vs-sanic-vs-japronto and finding it to have the highest throughput.
The API ran on 3 EC2 nodes in 3 regions behind ELB loadbalancers with Route53 latency based routing to route requests to the region closest to the user to ensure low latency.
Choosing a new Tech stack
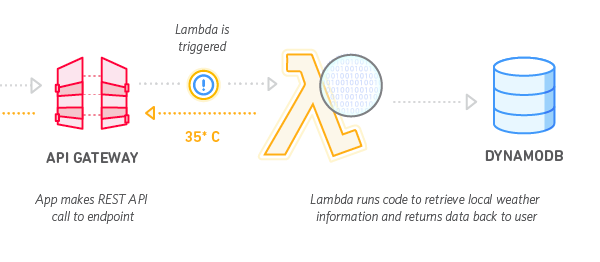
An Example Weather API using our current stack
Around this time I started to seriously look into using API Gateway with AWS Lambda given their:
- Favorable pricing — about $3.50 per million on API Gateway and $0.20 per million for AWS Lambda.
- Infinite scale and high throughput — the account limit on API Gateway is 10, 000 requests per second or about 864M calls daily. A limit that is possible to lift by opening a support request.
This also made it economically viable to have endpoints in numerous AWS regions to provide low latencies to all our users all over the globe.
Designing a multi-regional API Gateway API
There were a number of architectural challenges that had be solved to make this viable.
- Each lambda function in each region needed to be able to lookup usage data in a database in the same region to minimize latency
- I needed to figure out a way to determine the number of API calls made by each IP Address, Referer and API Key.
- A means to sync the usage data in all regions. For example if Route53 sent 10 000 requests to our Sydney endpoint then decided to send the next 50 000 to our Seoul endpoint (depending on which had the least network latency at that point in time). Each lambda function would need to know that the user had made 60 000 requests in total to properly handle rate limiting.
- Authorization — API Gateway provides usage plans and API key generation and allows you to link an API key to a usage plan. With the added advantage that you don’t get charged for requests users make beyond their quotas. However I couldn’t use this because it was important to me to provide a no sign-up, no credit card free tier.
With quite a bit of work, I was able to solve these problems in creative ways.
Accessing the usage data locally (for each lambda function)
The obvious solution for this was to use Dynamodb, it was cost effective at scale and fast! With the first 200M requests per month being free.
Dynamodb also provides consistently low read latencies of 1–2 ms.
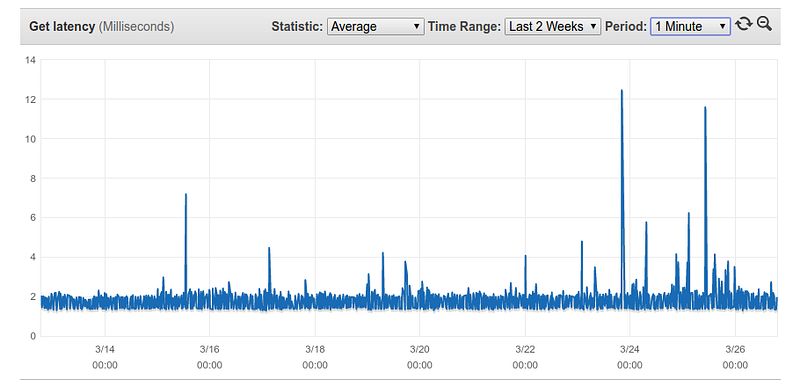
And this can be sped up into the microsecond range with Dynamodb Accelarator (DAX).
DAX takes performance to the next level with response times in microseconds for millions of requests per second for read-heavy workloads.
Collecting usage data for all identifiers
The next challenge was how to count in real time the number of requests made per IP address, Referer or API key.
The simplest most direct way to do this would be to update a count in a dynamodb table on each call.
However this would introduce database writes on each call to our API, potentially introducing significant latency.
I was able to find a simple and elegant solution to this:
- First, print a log (a JSON object) with all the request identifiers on each request. That is the IP address, Referer and API key if present. Really just; ```print(event) ```
- Add a Cloudwatch Subscription Filter to the Cloudwatch Log Stream of each Lambda function in each region and push all the logs into a Kinesis stream. This would allow me to process log events from every region in a central place. I chose Kinesis over SQS (Amazon’s Simple Queue Service) because of the ability to play back events. SQS deletes the event as soon as a consumer reads it. And I wanted the ability to be able to recover from node failures and data loss.
- Read from the Kinesis stream and update a Local Dynamodb instance with the usage data
- Use the Dynamodb Cross Regional Replication Library to stream all changes to my local dynamodb instance to all the tables in all regions in real time.
Authenticating Requests
I handle this by replicating keys to every region on signup, so that no matter what endpoint a user hits, the lambda function they hit can verify their key by checking in it’s local Dynamodb table within a millisecond. This also stores the user’s plan quota and can in a single read verify the key and if it exists get the plan quota to compare usage against and determine whether to accept or reject the request.
How this has fared
Today we serve 25M API calls monthly, about 1M calls daily.
Majority of them in under 30ms, providing the fastest IP Geolocation Lookup over SSL in the industry.
Hyperping.io
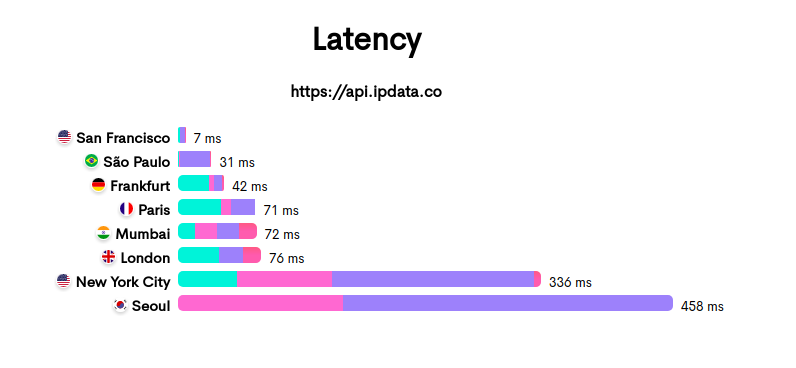
Our Status Page
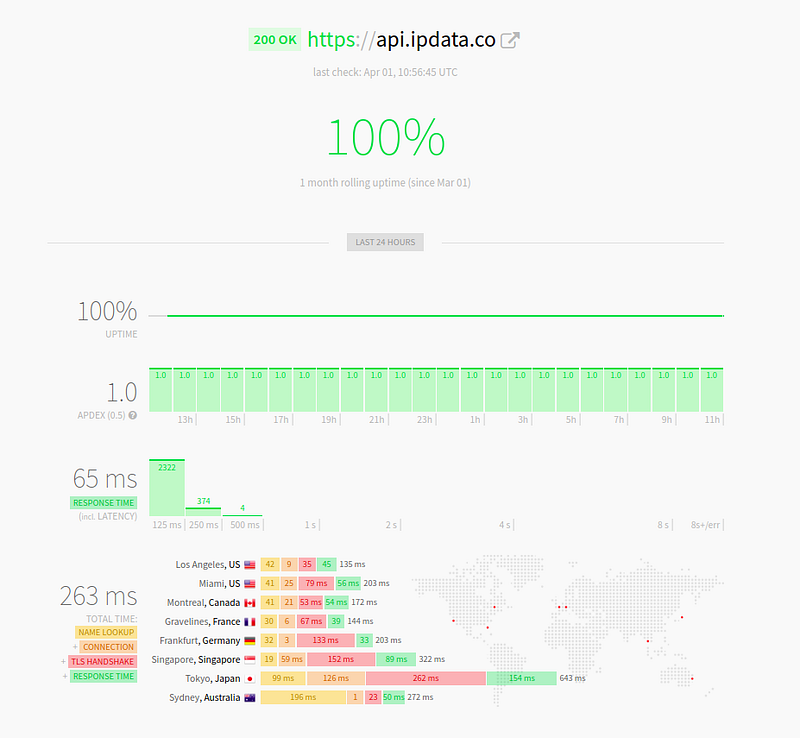
Latency is pretty much the biggest reason developers shy from using third party APIs for GeoIP lookups.
However our low latencies and redundant global infrastructure are slowly drawing large businesses to our service.
Costs

Lessons
- Cloudwatch can be surprisingly costly — and not log storage — we only store cloudwatch logs for 24hrs. Alarms, metrics and cloudwatch requests can really add up.
- On API Gateway the more requests you get the lower your latencies will be due to fewer cold starts, because of this I’ve seen latencies as low as 17ms in our busiest region (Frankfurt) to 40ms in our less busy regions such as Sydney.
- Dynamodb is fast and will cost you less than you think (or not, see https://segment.com/blog/the-million-dollar-eng-problem/). I initially thought I’d get charged per the number of RCUs and WCUs I’d provision. However billing seems to be only par usage, so if you provision 1000 RCUs and 1000 WCUs but only use 5 RCUs and WCUs you’ll only get charged for your usage. This aspect of Dynamodb pricing was a bit tough to wrap my head around at the beginning.
- Increasing your lambda RAM can halve your execution time and make response times more consistent (as well as double your costs!)
- Kinesis has proven to be very reliable under high throughput. Relaying all our log events for processing in near real time.
- Local Dynamodb is only limited by your system resources, which makes it great for running table scans or queries (for example when generating reports) that would otherwise be expensive to do on AWS’s Dynamodb. Keep in mind that Local Dynamodb is really just Dynamo wrappings around SQLite :). It’s useful and convenient for our usecase but might not be so for you.
Notes
- AWS announced Dynamodb Global tables at Re:invent last year which syncs all writes in all tables — across regions — to each other. We’re currently not moving to this as it’s only available in 5 regions.
- Amazon also introduced Custom Authorizers of the
REQUESTtype. Which would potentially allow you to rate limit by IP Address as well as any header, query or path parameter.



