Birth of the NearCloud: Serverless + CRDTs @ Edge is the New Next Thing

Kuhiro 10X Faster than Amazon Lambda
This is a guest post by Russell Sullivan, founder and CTO of Kuhirō.
Serverless is an emerging Infrastructure-as-a-Service solution poised to become an Internet-wide ubiquitous compute platform. In 2014 Amazon Lambda started the Serverless wave and a few years later Serverless has extended to the CDN-Edge and beyond the last mile to mobile, IoT, & storage.
This post examines recent innovations in Serverless at the CDN Edge (SAE). SAE is a sea change, it’s a really big deal, it marks the beginning of moving business logic from a single Cloud-region out to the edges of the Internet, which may eventually penetrate as far as servers running inside cell phone towers. When 5G arrives SAE will be only a few milliseconds away from billions of devices, the Internet will be transformed into a global-scale real-time compute-platform.
The journey of being a founder and then selling a NOSQL company, along the way architecting three different NOSQL data-stores, led me to realize that computation is currently confined to either the data-center or the device: the vast space between the two is largely untapped. So I teamed up with some smart people and we created the startup Kuhirō: a company dedicated to incrementally pushing pieces of the Cloud out to the edge, gradually creating a decentralized cloud very close to end-users, a NearCloud.
We decided the foundations of this NearCloud would be compute & data so we are beginning with a stateful SAE system which will serve as a springboard for subsequent offerings (e.g. ML inference, real-time-analytics, etc…). At many CDN edges, we run customer business logic as functions which read and write real-time customer-data. We put in the effort to make a CRDT-based data-layer that (for the first time ever) delivers low-latency dynamic web-processing on shared-global-data from the CDN edge. Kuhirō enables customers to move the dynamic latency-sensitive parts of their app from the cloud to the edge, customer apps become global-scale real-time applications with Kuhirō handling the operations and scaling.
Serverless at the Edge Architecture
SAE systems resemble Content-Delivery-Networks (CDNs) in terms of physical presence: mini data-centers referred to as Points-of-Presence (PoPs) are placed in strategic positions across the nation (or globe) to serve as many end-users with the lowest latency possible. SAE customers switch the domain-names in their URLs to the SAE provider’s domain-name, this change sends end-users’ web-requests to a nearby SAE PoP where customer functions run customer business logic and generate responses.
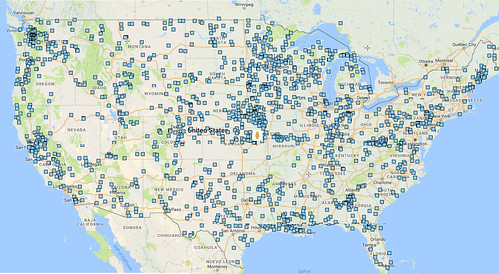
In the US alone, SAE systems can expand to be present in 300K cell towers and can decentralize the Cloud out to all of these blue dots, which for 99% of you is within a few miles.
Benefits of Decentralization
In general terms, decentralization yields benefits in bandwidth, latency, & robustness. To illustrate these benefits let’s examine a brick and mortar example of a decentralized system: Amazon’s fulfillment centers. These humongous physical buildings are what make Amazon Prime’s 2-day delivery possible on a nationwide scale: goods are shipped directly from many decentralized physical locations.
Benefits of decentralizing fulfillment centers:
Latency: Amazon Prime aims to place fulfillment centers within a 2-day delivery-vehicle drive to large population centers: Latency is the heart and soul of Prime.
Bandwidth: The more fulfillment centers in use at Amazon, the less goods each individual fulfillment center needs to process to fulfill the entirety of Amazon’s orders: Prime can scale better wherever demand increases.
Robustness: If the Silicon Valley (located in Newark CA) fulfillment center runs out of delivery trucks or is devastated by an earthquake, orders will be fulfilled from other CA centers (Stockton, Tracy, Patterson): The show goes on w/ only a small hiccup, even in the event of a natural disaster.
SAE systems function similarly to Amazon’s fulfillment centers:
Latency: Edge Points-of-Presence (PoPs) are placed in co-locations or cloud regions with low latency to large population centers.
Bandwidth: Each PoP’s main responsibility is to service a single large closeby population center autonomously, requests do not go back to a central system: Load is distributed and can be scaled better.
Robustness: If a PoP is saturated with requests or devastated by an earthquake load is immediately shifted to nearby PoPs.
Basically all Internet applications benefit from Decentralization
Decentralization’s three main benefits: Latency, Bandwidth, and Robustness are valuable across many Internet verticals (e.g. Web, Mobile, Gaming, Advertising, AR/VR, Maps, etc...).
The old network saying: “Latency is King” also applies to modern web-applications. Decreased latency increases revenues by improving user experience in many different web/mobile applications (1,2,3). Lower latency benefits verticals (e.g. Gaming, Advertising, Maps) where latency is essential to be competitive. Finally, in the near-future certain verticals (AR/VR, autonomous vehicles) will require low-latency NearClouds to truly deliver.
Benefits in bandwidth and robustness are priceless for companies who do not want to worry about operating and scaling the dynamic parts of their systems when load spikes, a DDoS attack happens, or a natural or human-error disaster happens.
Almost any Internet application can benefit by utilizing the NearCloud as an important incremental improvement/upgrade.
Serverless provides Multi-tenancy & Scale @Edge
Now that the benefits and beneficiaries of the NearCloud have been discussed, let’s explore why Serverless is the right infrastructure choice. Let’s start by comparing the differences between the Edge and the Cloud in terms of physical presence.
Single cloud regions can have well over 100K servers whereas Edge PoPs are drastically smaller (e.g. 10-100 machines). PoP hardware resources are far scarcer than Cloud resources.
Imagine providing Infrastructure-as-a-Service to 10K customers on 10 machines. Can you give each customer a Virtual Machine? No … you can’t even give him his own customizable container, there simply isn’t enough aggregate compute and storage to run 10K customers’ infrastructure on 10 machines. So you pick a smaller unit of compute: Functions … Functions-as-a-Service, AKA Serverless. Can you put 10K customers’ functions on 10 machines? Yes ... you can put many orders of magnitude more functions than that on 10 machines :)
Serverless’ inherent low resource usage is a perfect match for Edge PoPs’ small resource footprints.
State of SAE: Up-and-coming but Stateless
So where is SAE right now? What is the current state of SAE? As a very young field (debut in 2016) the number of companies offering SAE is small but growing. The two most interesting offerings are Cloudflare Workers and Amazon Lambda@Edge.
Both approaches are very secure and both provide minimal IaaS@Edge in the form of Serverless, but they differ in terms of flexibility and performance.
|
|
Cloudflare Workers | Amazon Lambda@Edge |
| Architecture | In all ~120 PoPs in Cloudflare’s CDN, customer functions are run in a modified heavily-sandboxed Javascript V8 engine. Individual functions run in JS sandboxes much as a browser runs individual websites’ JS in sandboxes. | In all ~95 PoPs in Amazon’s Cloudfront CDN, Lambda@Edge runs a single customer function per container. Currently only Node.js is supported, but the container approach makes adding additional languages straightforward. |
| Strength | Performance: no context switch when different customers run functions, very low memory consumption per function call, no need to spin containers up & down. | Flexibility in runtime languages (eventually). Compatible w/ Amazon’s larger stack. |
| Data-layer | none | none |
Stateless Computation is LAME
Unfortunately neither Cloudflare Workers nor Lambda@Edge offer dynamic data options, both offer only compute functionality. Lack of dynamic data capabilities (AKA stateless) limits SAE functionality to rewriting requests/responses based on client state (e.g. URL-Parameters, Cookie, User-agent header) or origin state (e.g. Etag, Cache-Control headers).
Stateless compute is more akin to network routing than it is to normal programming: useful for intelligent load balancing and request/response rewriting but not much more. Compute with state is the classic environment for computing.
Think about if Amazon stored all of its products in a single central location and fulfillment centers only had the capacity to rewrite incoming orders or repackage outgoing deliveries: the killer app Amazon Prime would not be possible, we would be back in the dark days when we got our online orders in weeks not days.
Edge-data’s Dirty Little Secret: Data-conflicts
The reason SAE offerings are currently stateless is that adding a data-layer to many (~100) geographically distant PoPs has a ton of subtle complexities.
In a perfect world we would just add a DB to each edge PoP, our edge functions would read/write to this local DB, which would replicate to the other PoPs’ DBs. The problem with this approach is a classic distributed systems problem: as soon as you divide a centralized data-store into multiple decentralized data-stores replicating in a mesh you inevitably get data-conflicts and the further the geographical distance between the decentralized nodes the higher the incidence of data-conflicts.
There are two major approaches to decentralizing data: consensus-based and CRDT-based. Both have pros and cons and sweet-spots in the distributed data world. Both approaches will be examined later in this post.
Edge Replication: Who sends what, where, when, how?
Now we will start deep diving into adding a data-layer to SAE by examining the uniqueness of replicating data in SAE systems.
In SAE when data is modified at a single PoP, where should the replication go? To all PoPs, to a subset of PoPs, or to no other PoPs*? The answer depends on the data in question … so the overall answer is all three flows need to be supported.
*It should be noted all modifications are also replicated to a (centralized) destination for backup purposes.
An analogy for SAE replication is to imagine a spectrum that begins with data replicated for a single-user who is pinned to a single PoP and ends with data replicated for all-users replicating data between all PoPs.
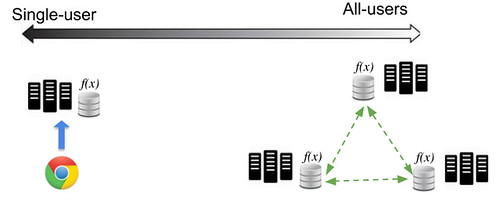
The single-user replication flow is simple: data is authored at a PoP and backed up. The all-users replication flow is a continuous multi-directional peer-to-peer data-broadcast (plus backup). An example of replication in the middle of the spectrum would be group-data, for instance an online group of users’ data (e.g. a soccer team). Group data is authored on a small number of PoPs and replicated between them.
During error conditions the analogy breaks down some: single-user flows become more complicated than the description above. A single-user can move to another PoP during permanent and temporal PoP failures as well as for traffic steering purposes. For this reason, single-user flows during error conditions may require concurrent replication from multiple PoPs to multiple PoPs. (i.e. group flow).
To make matters worse, the all-users flow at high modification rates can become a self-inflicted DDoS attack. To deal with this risk, a high-volume all-users flow can trade latency for performance and adopt a coalesce-and-batch approach, which scales beautifully.
Replicating data at the edge is unique and does not match the flow of existing data-stores therefore we need a new technology to enable it.
CRDTs are the Solution for State at the Edge
Fortunately both the complexities and peculiarities of state at the edge can be handled by a body of data structures and related algorithms known as Conflict-free Replicated Data Types (CRDTs). CRDTs allow actors to autonomously and concurrently modify data and then automatically resolve data-conflicts with zero consensus. These attributes (autonomy/zero-consensus & automatic-conflict-resolution) are base requirements for a low latency SAE platform.
Autonomy means PoPs can process requests locally and respond to end-users with predictable low latency, no need to wait on achieving consensus between PoPs that may be 1000s of miles apart. PoPs running autonomously implicitly run concurrently and concurrent modifications inevitably lead to data-conflicts. CRDTs automatically resolve data-conflicts across many different data structures and provide a guarantee called Strong Eventual Consistency.
CRDTs are a perfect fit for low latency SAE systems, they do have drawbacks (explored later) but overall they serve the space better than consensus based solutions.
Consensus at the Edge is SLOOOOOW
It is worth exploring why consensus based systems are a poor fit for SAE. The leading geo-distributed consensus-based data-layer is Google Spanner. A quote from the seminal Spanner paper:
Clients and zones were placed in a set of datacenters with network distance of less than 1ms.
Spanner was not designed to span significant geographic distance and simultaneously achieve low latency commits. Spanner is a two-phase-commit data-store, meaning each transaction requires two round trips to complete. Round trips between the US east and US west coast are ~100ms, meaning 2PC would take ~200ms. If your app sequentially modifies the same data 200ms commit latency equates to 5 transactions per second, which is simply too slow for many applications.
Example Shopping Demo
Enough theory, let’s check out an example of how an application runs on the NearCloud. We wrote a simple shopping demo:
Here's a link to a working shopping demo, click around, it’s live.
The functionality is simple: products are added, customers then register/login, browse product categories/brands, add products to their cart, and purchase products. Code can be found here, it is as uninteresting as demo shopping code should be, it’s straightforward Node.js code calling into a DocumentDB.
Here is a code snippet for adding a product to a user’s cart:
function add_product_to_user_cart(username, product_id, callback) {
// left-push product_id into user’s cart.items[]
var update = {operation : "INSERT", values : ["items", 0, product_id]};
var params = {TableName : "cart",
Key : {username : username},
Updates : [update]};
Data.update(params, callback);
}
This is standard code, there are no primitives for CRDT calls in the code, CRDT functionality is abstracted away and implemented deep in the data-layer. Data modeling for the entire demo uses nothing more than JSON data types: {number, string, object, array}.
One aspect of Kuhirō’s API we invested considerable effort into was into API compliance with other cloud offerings. We feel strongly that Serverless as a technology should have as little vendor lock-in as possible, so our offerings are simple to switch back and forth between Cloud providers and Kuhirō.
Kuhirō is compatible at the code, config, and data levels with Amazon Lambda and DynamoDB. The exact same demo shopping code runs on Lambda. Here's a link to the demo, it’s live, click on stuff. It’s literally the same code including calls into the data-layer. Switching back and forth from Lambda+DynamoDB to Kuhirō is possible via a single command line tool (once registration is completed).
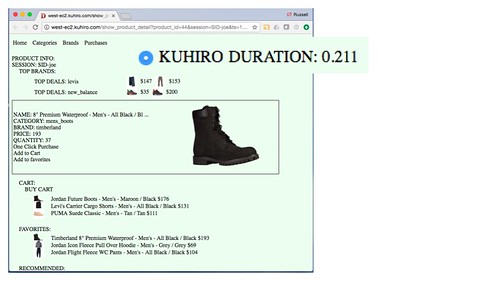
Here's a screen shot of the EC2 demo:
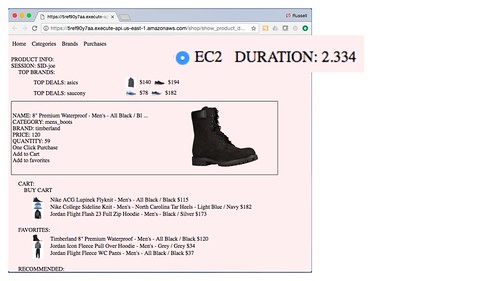
Notice the duration number in both screen shots. The Kuhirō version is much faster than EC2.
Kuhirō Delivers 5-10X Improvement in Latency to End-Users
The demo shows the benefits of running customer business logic at the end, for west coast users the demo runs 5-10X faster on Kuhirō than Lambda, for east coast users more like 2-4X (Lambda is using us-east-1 in VA), and for international users as high as 50X faster. In addition to running in multiple PoPs spread out over the globe, we have invested in minimizing the latency throughout our stack.
Decreasing latency has been proven to have direct impacts on increasing revenues (1,2,3,4,5) and Kuhirō represents a new tool for applications to speed up their apps, improve their UX, and maximize potential revenues.
Kuhirō Delivers Ridiculous Robustness
Another demo (video) we did about a year ago showcases the robustness of Kuhirō’s data-layer. At about 12 minutes in, we did “Some Bad Bad Things” to the data-layer: we started randomly killing different nodes in different data-centers, then killing entire data-centers, then reviving stuff, it was real chaos. The video visually shows just how ridiculous the robustness of CRDT-based systems can be.
This data-layer robustness not only helps during routine machine failures and less frequent data-center level outages, it also elegantly degrades service during DDoS attacks.
Mix Decentralization and Centralization As Needed
Switching our demo shopping app from a centralized to decentralized architecture lets us explore the concepts developers need to understand when running decentralized.
For 30 of the 32 shopping-demo-actions, the distributed and not-distributed architectural flows are the same, these flows (e.g. customer-login, browse-products, add-to-cart) happen naturally at the edge: the requisite data is present at the edge cache and modifications are naturally modeled in CRDTs (e.g. add item to customer-cart-array). The two cases that do not fit this pattern require a single point of truth (SPOT).
The SPOT cases are registering a username and purchasing a product. These actions reserve or withdraw from a finite inventory and are therefore non-distributable (e.g. two PoPs concurrently registering the username ‘Joe’ or two users at different PoPs concurrently purchasing the final toothbrush in inventory).
SPOTs are CRDTs’ kryptonite, the anti-CRDT, they are by definition non-distributable. Luckily research has shown SPOT-transactions constitute only ~13% of DB writes.
Kuhirō has a simple mechanism for supporting SPOT function calls. We add the capability to run a function at a central PoP (called CPoP). This functionality satisfies almost all SPOT use case requirements (e.g. registering username: ‘Joe’ will always go to CPoP where it will either be reserved or free). CPoP is the Single Point Of Truth. Using a Central-PoP for SPOT-transactions allows the entire application to run on a single system under a single API.
SPOT handling can also take a centralized/decentralized hybrid approach: In the case of purchases, we define a threshold of 10 (based on our knowledge of our website’s concurrent purchase rates) and above this threshold we allow the purchase to be done in a distributed fashion while below the threshold the action is a SPOT purchase. It’s a one line code change and provides the best of both worlds: above threshold [low latency, high bandwidth, extreme robustness] and below threshold [SPOT guarantees].
The Verdict: Kuhirō for Low Latency to End-Users
Let’s compare running our shopping-demo app centralized and decentralized:
|
|
Kuhirō Decentralized | Centralized |
| Round-trip latency to end-users | World-wide major population centers consistently 10-40ms | Varies w/ distance between data-center and end-users, worldwide peak over 400ms |
| Fault Tolerance | Multi-homed: natural disaster tolerant Clustered DB: node failure tolerant | Clustered DB: node failure tolerant |
| API | Serverless + DocumentDB API | Serverless + DocumentDB API |
| Tooling | New service: immature | 3 yrs old: maturing |
| Conceptual Complexity | Requires reasoning about concurrency and SPOTs | Standard Serverless concepts |
Summary: Run latency-sensitive serverless use-cases decentralized for large benefits in latency & robustness. Run non-latency-sensitive serverless use-cases centralized for benefits in maturity.
Verdict: Use BOTH as appropriate, exploit the lack of lock-in.
Serverless at the CDN Edge is Now, NearCloud is Now => Kuhirō is Now
The NearCloud sounds futuristic but it has already begun with stateful serverless at the edge systems. SAE’s main benefit is predictable low latency to end-users on a global scale: your global user base can call into cloud-based business logic in real-time. The additional benefits of increased robustness, including graceful degradation to DDoS attacks, and all of the goodies that come along with Serverless: pay-for-what-you-use, provider-handles-operations/scaling, and ease-of-coding make SAE systems extremely attractive to devops teams.
Kuhirō is in (stealth) Beta and accepting Beta customers for our NearCloud system. Kuhiro’s Stateful Serverless at the Edge system enables you to create new decentralized apps from scratch or to decentralize your existing Serverless apps (e.g. on Amazon Lambda + DynamoDB) w/o code or data changes, reaping extreme low latency to end-users, pushing your app into real-time on a global-scale.
Interested in becoming a Beta customer or just want to geek out on the NearCloud, email me at russ@kuhiro.com.



