Jeff Dean on Large-Scale Deep Learning at Google

If you can’t understand what’s in information then it’s going to be very difficult to organize it.
This quote is from Jeff Dean, currently a Wizard, er, Fellow in Google’s Systems Infrastructure Group. It’s taken from his recent talk: Large-Scale Deep Learning for Intelligent Computer Systems.
Since AlphaGo vs Lee Se-dol, the modern version of John Henry’s fatal race against a steam hammer, has captivated the world, as has the generalized fear of an AI apocalypse, it seems like an excellent time to gloss Jeff’s talk. And if you think AlphaGo is good now, just wait until it reaches beta.
Jeff is referring, of course, to Google’s infamous motto: organize the world’s information and make it universally accessible and useful.
Historically we might associate ‘organizing’ with gathering, cleaning, storing, indexing, reporting, and searching data. All the stuff early Google mastered. With that mission accomplished Google has moved on to the next challenge.
Now organizing means understanding.
Some highlights from the talk for me:
Real neural networks are composed of hundreds of millions of parameters. The skill that Google has is in how to build and rapidly train these huge models on large interesting datasets, apply them to real problems, and then quickly deploy the models into production across a wide variery of different platforms (phones, sensors, clouds, etc.).
The reason neural networks didn’t take off in the 90s was a lack of computational power and a lack of large interesting data sets. You can see how Google’s natural love of algorithms combined with their vast infrastructure and ever enlarging datasets created a perfect storm for AI at Google.
A critical difference between Google and other companies is that when they started the Google Brain project in 2011, they didn’t keep their research in the ivory tower of a separate research arm of the company. The project team worked closely with other teams like Android, Gmail, and photos to actually improve those properties and solve hard problems. That’s rare and a good lesson for every company. Apply research by working with your people.
This idea is powerful: They’ve learned they can take a whole bunch of subsystems, some of which may be machine learned, and replace it with a much more general end-to-end machine learning piece. Often when you have lots of complicated subsystems there’s usually a lot of complicated code to stitch them all together. It’s nice if you can replace all that with data and very simple algorithms.
Machine learning will only get better, faster. A paraphrased quote from Jeff: The machine learning community moves really really fast. People publish a paper and within a week lots of research groups throughout the world have downloaded the paper, have read it, dissected it, understood it, implemented some extensions to it, and published their own extensions to it on arXiv.org. It’s different than a lot other parts of computer science where people would submit a paper, and six months later a conference would decide to accept it or not, and then it would come out in the conference proceeding three months later. By then it’s a year. Getting that time down from a year to a week is amazing.
Techniques can be combined in magical ways. The Translate Team wrote an app using computer vision that recognizes text in a viewfinder. It translates the text and then superimposes the translated text on the image itself. Another example is writing image captions. It combines image recognition with the Sequence-to-Sequence neural network. You can only imagine how all these modular components will be strung together in the future.
Models with impressive functionality are small enough run on Smartphones. For technology to disappear intelligence must move to the edge. It can’t be dependent on network umbilical cord connected to a remote cloud brain. Since TensorFlow models can run on a phone, that might just be possible.
If you’re not considering how to use deep neural nets to solve your data understanding problems, you almost certainly should be. This line is taken directly from the talk, but it’s truth is abundantly clear after you watch hard problem after hard problem made tractable using deep neural nets.
Jeff always gives great talks and this one is no exception. It’s straightforward, interesting, in-depth, and relatively easy to understand. If you are trying to get a handle on Deep Learning or just want to see what Google is up to, then it's a must see.
There’s not a lot of fluff in the talk. It’s packed. So I’m not sure how much value add this article will give you. So if you want to just watch the video I’ll understand.
As often happens with Google talks there’s this feeling you get that we’ve only been invited into the lobby of Willy Wonka’s Chocolate factory. In front of us is a locked door and we're not invited in. What’s beyond that door must be full of wonders. But even Willy Wonka’s lobby is interesting.
So let’s learn what Jeff has to say about the future…it’s fascinating...
What is Meant by Understanding?
When a human is shown a street scene they have no problem picking out text from the scene, understanding that one store sells souvenirs, one store has really low prices, and so on. Until recently computers have not been able to extract this information from images.

If you really want to understand the physical world from imagery a computer needs to be able to pick out interesting bits of information, read the text, and understand it.
Small mobile devices dominate computer interaction both today and in the future. You need different kinds of interfaces for those devices. You need to really be able to understand and generate speech.
Take a query: [car parts for sale]. Old Google would match the first result because the keywords match, but the better match is the second document. Really understanding what the query means at a deep level, not at the superficial word level, is what you need to build good search and language understanding products.

A Little History of Deep Neural Nets at Google
The Google Brain project started 2011 and focussed on really pushing the state-of-the-art of what can be done with neural networks.
Neural networks have been around for a long time. Invented in the 60s and 70s, popular in the late 80s and early 90s, they faded away. Two problems: 1) A lack of the computational power necessary to train large models meant neural nets couldn’t be applied to larger problems on larger interesting data sets. 2) There was a lack of large and interesting data sets.
Started working with just a few product groups at Google. Over time as groups released something that was good or solved some problem they weren’t previously able to solve, word got around and more teams would go to them to help solve problems.
Some of the products/areas that make use of deep learning technology: Android, Apps, drug discovery, Gmail, image understanding, maps, natural language, photos, robotics, speech translation, and many others.
The reason deep learning can be applied across such a diverse set of projects is they involve the same set of building blocks that apply to different areas: speech, text, search queries, images, videos, labels, entities, words, audio features. You can feed in one kind information, decide what kind information you want out, collect together a training data set that is indicative of the function you want to compute, and off you go.
These models work so well because you feed in very raw forms of data, you don’t have to hand engineer lots of interesting features, the power of the model is it is able to decide what’s interesting about the data set automatically from just observing lots and lots of examples.
You can learn common representations, potentially across domains. A ‘car’ can mean the same thing as an image of a car, for example.
They’ve learned they can take a whole bunch of subsystems, some of which may be machine learned, and replace it with a much more general end-to-end machine learning piece. Often when you have lots of complicated subsystems there’s usually a lot of complicated code to stitch them all together. It’s nice if you can replace all that with data and very simple algorithms.
What is a Deep Neural Net?
Neural nets learn a really complicated function from data. Inputs from one space are transformed into outputs in another space.
This function is not like x2, it’s a really complicated function. When you feed in raw pixels, like a cat, for example, the output would be an object category.

-
The “deep” in Deep Learning refers to the number of layers in the neural network.
-
A nice property of depth is that the system is composed of a collection of simple and trainable mathematical functions.
-
Deep Neural Nets are compatible with a lot of machine learning styles.
-
For example, where you have an input that is a cat picture and an output where a human labeled the image as a cat, that’s called supervised learning. You can give lots of supervised examples to the system and you are going to learn to approximate a function that’s similar to the one it observes in those supervised examples.
-
You can also do unsupervised training where you are only given images and you don’t know what’s in them. The system can then learn to pick up on patterns that occur in lots of images. So even if you don’t know what to call the image it can recognize that there’s something in common with all these images that have a cat in them.
-
It’s also compatible with more exotic techniques like reinforcement learning, which a very important technique that is being used as one piece of AlphaGo.
-
What is Deep Learning?
Neural net models are based loosely on how we think brains behave. It’s not a detailed simulation of how neurons really work. It’s a simple abstract version of a neuron.
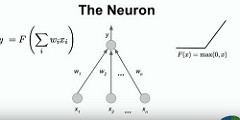
-
A neuron has a bunch of inputs. Real neurons can associate different strengths with different inputs. An artificial neural network tries to learn weights on all those edges that are the strengths associated with the different inputs.
-
Real neurons take in some combination of their inputs and the strengths and decide to fire or not to fire, a spike.
-
Artificial neurons do not just emit a spike, the emit a real number value. The function these neurons compute is the weighted sum of their inputs times the weights applied through some nonlinear function.
-
Typically the nonlinear function used today is a rectified linear unit (max(0,x)). In the 90s a lot of the nonlinear functions were much smoother sigmoid or tanh functions. It has the nice property of giving true zeros when the neuron doesn’t fire as opposed to values which are close to zero which can help you when optimizing the system.
-
For example, if a neuron as three inputs X1, X1, X3 with the weights -0.21, 0.3, and 0.7, the calculation would be: y = max(0, -.0.21*x1 + 0.3*x2 + 0.7*x3).
-
-
In determining if an image is a cat or dog the image will be put through a series of layers. Some of the neurons will fire or not based on their inputs.
-
The lowest layer neurons will look at little patches of pixels. The higher level neurons will look at the output of the neurons below and decide to fire or not.
-
The model will work its way up through the layers and say, for example, that it’s a cat. Which in this case is wrong, it’s a dog (though I thought it was cat too, a dog in a hamper?).
-
A signal that this was the wrong decision feeds back into the system which will then make adjustments to the rest of the model to make it more likely the output will be dog when the image is viewed next time.
-
That’s the goal of a neural net, to make little adjustments to the weights on all the edges throughout the model to make it more likely you get the example right. You do this in aggregate across all the examples so that in aggregate you get most of the examples right.
-
-
The learning algorithm is really simple. While not done:
-
Pick a random training example “(input, label)”. For example the cat picture with the desired output, ‘cat’.
-
Run the neural network on “input” and see what it produces.
-
Adjust weights on edges to make output closer to “label”
-

-
How do you adjust the weights on the edges to make the output closer to label?
-
Backpropagation. Here’s the recommended explanation: Calculus on Computational Graphs: Backpropagation.
-
The chain rule of calculus is used to determine at the top of the neural net when the choice was cat instead of dog you understand how to adjust the weights at the top layer to make it more likely to say dog.
-

You need to go in the direction of the arrow with the weights to make it more likely it will say dog. Don’t take a big step because it’s a complicated uneven surface. Take a very small step to make it more likely the result will be dog next time. Through lots of iterations and looking at examples the more likely the result will be dog.
Through the chain rule you can understand how changes in parameters of the lower layers will impact the output. That means changes in the network can be rippled through all the way back to the input and make the whole model adapt and be more likely to say dog.
Real neural networks are composed of hundreds of millions of parameters so you are making adjustments in a hundred million dimension space and trying to understand how that impacts the output of the network.
Some Nice Properties of Neural Nets
-
Neural nets can be applied to lots of different kinds of problems (as long as you have lots of interesting data to understand).
-
Text: there’s trillions of words of english and other languages. There’s lots of aligned text where there are translated versions in one language and another at a sentence by sentence level.
-
Visual data: billion of images and videos.
-
Audio: tens of thousands of hours of speech per day.
-
User activity: there are a lot different applications generating data. Examples are queries from search engines or people marking messages spam in email. There’s lots of activity you can learn from and build intelligent systems.
-
Knowledge graph: billions of labelled relation triples.
-
-
Results tend to get better if you throw more data at them and you make your model bigger.
-
If you throw more data at a problem and don’t make your model bigger at some point the model's capacity is saturated with learning the more obvious facts about your data set.
-
By increasing the size of the model it can remember not just the obvious things but it can remember the subtle kinds of patterns that occur maybe in only a tiny fraction of the examples in the data set.
-
By building bigger models on more data a lot more computation is needed. A lot of what Google has been working on is how to scale the amount computation to throw at these problems in order to train bigger models.
-
Where does Deep Learning Have a Significant Impact at Google?
Speech Recognition
This was one of the first teams the Google Brain team worked with to deploy neural nets. They helped them deploy a new acoustic model that was based on neural nets instead of the hidden Markov model they were using.
The problem of the acoustic model is to go from 150 milliseconds of speech to predicting what sound is being uttered in the middle 10 milliseconds. Is it, for example, a ba or ka sound? Then you have a whole sequence of these predictions and then you stitch them together with a language model to understand what the user said.
Their initial model reduced word recognition errors by 30%, which is a really big deal. Since then the speech team has been working on more complicated models and advanced networks to further reduce the error rate. Now when you speak into your phone, voice recognition is much better than it was three or five years ago.
ImageNet Challenge
-
About 6 years ago the ImageNet data set was released. At about a million images it was at that time one of the biggest datasets for computer vision. The release of this huge dataset pushed forward the field of computer vision.
-
Images were placed in about 1000 different categories with about a 1000 images for each category.
-
There are a thousand different pictures of leopards, motor scooters, and so on.
-
A complicating factor is not all the labels are correct.
-
-
The goal is to generalize to new kinds of images. Can you say for a new image if that’s a leopard or that’s a cherrie?
-
Before neural nets were used in the challenge the error rates were around 26%. In 2014 Google won the challenge with an error rate of 6.66%. In 2015 the error rate was down to 3.46%.
-
It’s a big and deep model. Each box is a like whole layer of neurons that’s doing convolution operations. Here’s the paper: Going Deeper with Convolutions.
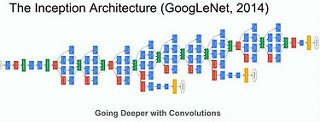
Andrej Karpathy, a human, took the challenge and had an error rate of 5.1%. You can read about his experience at: What I learned from competing against a ConvNet on ImageNet.
What are neural net models good at?
- The models are very good at making fine level distinctions. Computers are good at distinguishing dog breeds, for example, where humans aren’t as good. Where a human might see a flower and say it’s a flower, the computer can tell if it’s a “hibiscus” or a “dahlia”.
- The models are good at generalizing. Different kinds of meals, for example, that don’t look visually similar, will still be labeled properly as “meal.”
- When the computer makes a mistake the errors are sensible as to why. A slug, for example, looks a lot like a snake.
Google Photos Search
The ability to look at pixels and understand what’s in the image is a powerful one.
The Google Photos team implemented the ability to search photos without tagging them. You can find pictures of statues, yoda, drawings, water, etc without having the pictures being tagged.
Street View Imagery
In street view imagery you want to be able to read all the text. This is a much finer more specific visual task.
You need to be able to first find text in an image. A model was trained to essentially predict a heat map of pixels, which pixels contain text and which don’t. The training data was polygons drawn around pieces of text.
Because the training data included different character sets it has no problem finding text in multiple languages. It works with big fonts and small fonts; words that are close to the camera and words that are far away; in different colors.
It’s a relatively easy model to train. It’s a convolutional network that tries to predict per pixel if it contains text or not.
RankBrain in Google Search Ranking
-
RankBrain was launched in 2015. It’s the third most important search ranking signal (of 100s). More information at: Google Turning Its Lucrative Web Search Over to AI Machines.
-
Search ranking is different because you want to be able to understand the model, you want to understand why it is making certain decisions.
-
This was one on the Search Ranking Team’s hesitancies in using a neural net for search ranking. When the system makes a mistake they want to understand why is it doing that.
-
Debugging tools were created and enough understandability was built into the models to overcome this objection.
-
In general you don’t want to manually tweak parameters. You try to understand why the model is making that kind of prediction and figure out if it’s something related to the training data, is it mismatched to the problem? You may train on one distribution of data and apply to another. With search the distribution of queries you get everyday changes a little bit. Changes happen all the time because of events. You have to understand if your distribution is stable, like with speech recognition, the sounds people make don’t change very much. Queries and document contents change frequently so you have to make sure your model is fresh. More generally we need to do a better job building tools for understanding what’s going on inside these neural nets, figuring out what’s causing a prediction.
-
Sequence to Sequence Model
A lot of problems in the world can be framed as mapping one sequence to another. Sutskever, Vinyals, and Le at Google wrote a groundbreaking paper on this topic: Sequence to Sequence Learning with Neural Networks.
In particular, they looked at language translation, at the problem of translating English into French. Translating is really just mapping a sequence of English words into a sequence of French words.
Neural nets are very good at learning very complicated functions, so this model learns the function of mapping English to French sentences.
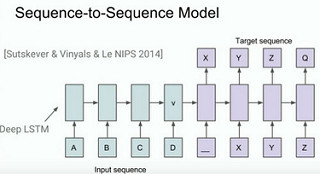
A sentence in one language is inputted one word at a time with an EOS (end of sentence) signal. The model is trained when is sees an EOS to start producing the corresponding sentence in the other language. The training data is language sentence pairs that mean the same thing. It just tries to model that function.
At every step it emits a probability distribution over all the vocabulary entries in your vocabulary. At inference time instead of training you need to do a little bit of a search. If you must maximize the probability at each word you aren’t necessarily going to get the most probable sentence. A search is done over the joint probabilities until a maximally probable sentence is found.
This system achieves state of the art on a public translation task. Most other translation systems are a bunch of hand coded or machine learned models for sub pieces of the problem rather than this full end-to-end learned system.
There has been an explosion of interest in this model because a lot of problems can be mapped to this sequence-to-sequence approach.
Smart Reply
-
Smart Reply is an example how Sequence-to-Sequence is used in a product. On a phone you want to be able to respond quickly to email and typing is a pain.
-
Working with the Gmail team they developed a system to predict likely replies for a message.
-
First step was to train a small model to predict if a message is the kind of message that would have a short reply. If so a bigger more computationally expensive model is activated that takes the message in as a sequence and tries to predict the sequence of the response word.
-
For example, to an email asking about a Thanksgiving invitation the three predicted replies are: Count us in; We’ll be there; Sorry we won’t be able to make it.
-
A surprising number of replies generated in the Inbox app are generated using Smart Reply.
-
Image Captioning
When generating an image caption you are trying to maximize the likely caption a human would write about an image given the pixels of the image.
Take the image models that were developed and the Sequence-to-Sequence models that were developed and plug them together. The image model is used as input. Instead of reading an English sentence one word at a time you look at the pixels of the image.
It’s trained to generate the caption. The training data set had images with five different captions written by five different people. A total of about 700,000 sentences were written about 100,000 to 200,000 images.
About a picture of a baby hugging a teddy bear the computer wrote: A close up of a child holding a stuffed animal; A baby is asleep next to a teddy bear.
It doesn’t have a human level of understanding. When it’s wrong the results can be funny.
Combined Vision + Translation
Techniques can be combined. The Translate Team wrote an app using computer vision that recognizes text in a viewfinder. It translates the text and then superimposes the translated text on the image itself (very impressive looking, at about 37:29).
The models are small enough that it all runs on the device!
Turnaround Time and Effect on Research
Train in a day what would take a single GPU card 6 weeks.
Google really cares about being able to turn around research quickly. The idea is to train models quickly, understand what worked well and didn’t work well, and figure out the next set of experiments to run.
A model should be trainable in minutes our hours, not days or weeks. It makes everyone doing this kind of research more productive.
How Do You Train Large Models Quickly
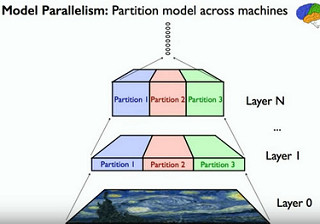
Model Parallelism
A neural net has lots of inherent parallelism.
All the different individual neurons are mostly independent of each other when you are computing them, especially if you have Local Receptive Fields, where a neuron accepts inputs from only a small number of neurons below it.
Work can be partitioned across different machines on different GPU cards. Only the data that straddles boundaries requires communication.
Data Parallelism
The set of parameters for the model you are optimizing should not be in one machine be in a centralized service so you can have many different replicas of the model that are going collaborate to optimize the parameters.
Read different random pieces of data (examples) during the training process. Each replica is going get the current set of parameters in the model, read a bit of data on what the gradient should be, figure out what adjustments it wants to make to the parameters, and send the adjustments back to the centralized set of parameter servers. The parameter servers will make the adjustments to the parameters. And the process repeats.
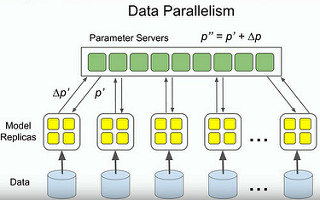
This can be done across many replicas. Sometimes they use 500 copies of the model across 500 different machines in order to optimize the parameters quickly and process a lot of data.
The process can be asynchronous where every silo is in its own loop, getting parameters, computing gradients and sending them back without any control or synchronization with the other ones. The downside is when the gradient comes back the parameters may have moved from when the computation was done. Turns out this is sort of OK for many kinds of models in practice up to 50 to 100 replicas.
The process can synchronous. One controller controls all the replicas. Both seem to work and have different strengths and weaknesses (not listed).
The next part of the talk is on TensorFlow, which I won’t cover here. This post is already too long.
Q&A
What do you do if you are not a large company like Google and don’t have access to large data sets? Start with a model that works well that’s trained on a public data set. Public data sets are generally available. Then do training on data that is more customized to your problem. You might only need a 1,000 or 10,000 examples that are labeled for your particular problem when you start with a data set that is similar and publically available. ImageNet is a good example of this process working.
What is your biggest mistake as an engineer? Not putting distributed transactions in BigTable. If you wanted to update more than one row you had to roll your own transaction protocol. It wasn’t put in because it would have complicated the system design. In retrospect lots of teams wanted that capability and built their own with different degrees of success. We should have implemented transactions in the core system. It would have been useful internally as well. Spanner fixed this problem by adding transactions.
Related Articles
- On HackerNews
- Ryan Adams with an awesome muggle accessible technical explanation of AlphaGo on the Machine Learning Music Videos episode of the Talking Machines podcast.
- TensorFlow
- Why Enrollment Is Surging in Machine Learning Classes
- Move Evaluation in Go Using Deep Convolutional Neural Networks
- In Defence of Strong AI: Semantics from Syntax
- The Chinese Room Argument
- Google: Multiplex Multiple Works Loads On Computers To Increase Machine Utilization And Save Money
- Google On Latency Tolerant Systems: Making A Predictable Whole Out Of Unpredictable Parts
- Google DeepMind: What is it, how does it work and should you be scared?
- Inside the Artificial Brain That's Remaking the Google Empire
- Neural Networks Demystified
- Hacker's guide to Neural Networks
- Neural Networks and Deep Learning
- Neural Networks (General)
- stephencwelch/Neural-Networks-Demystified
- Topics Course on Deep Learning UC Berkeley
- Machine Learning: 2014-2015
- Playing Atari with Deep Reinforcement Learning
- Human-level control through deep reinforcement learning



