Leveraging Cloud Computing at Yelp - 102 Million Monthly Vistors and 39 Million Reviews


This is a guest post by Yelp's Jim Blomo. Jim manages a growing data mining team that uses Hadoop, mrjob, and oddjob to process TBs of data. Before Yelp, he built infrastructure for startups and Amazon. Check out his upcoming talk at OSCON 2013 on Building a Cloud Culture at Yelp.
In Q1 2013, Yelp had 102 million unique visitors (source: Google Analytics) including approximately 10 million unique mobile devices using the Yelp app on a monthly average basis. Yelpers have written more than 39 million rich, local reviews, making Yelp the leading local guide on everything from boutiques and mechanics to restaurants and dentists. With respect to data, one of the most unique things about Yelp is the variety of data: reviews, user profiles, business descriptions, menus, check-ins, food photos... the list goes on. We have many ways to deal data, but today I’ll focus on how we handle offline data processing and analytics.
In late 2009, Yelp investigated using Amazon’s Elastic MapReduce (EMR) as an alternative to an in-house cluster built from spare computers. By mid 2010, we had moved production processing completely to EMR and turned off our Hadoop cluster. Today we run over 500 jobs a day, from integration tests to advertising metrics. We’ve learned a few lessons along the way that can hopefully benefit you as well.
Job Flow Pooling
One of EMR’s biggest advantages is instant scalability: every job flow can be configured with as many instances as needed for the task. But the scalability does not come for free. Themain drawbacks are 1) spinning up a cluster can take 5-20 minutes, and2) you are billed per hour or fraction thereof. This means if your job finishes in 2 hours 10 minutes, you are charged for the full three hours.

This may not seem like a big deal, until you start running hundreds of jobs and the wasted time at the end of a job flow starts adding up. To decrease the amount of wasted billing hours, mrjob implements “job flow pooling.” Instead of shutting down a job flow at the end of a job, mrjob keeps the flow alive in case another job wants to use it. If another job comes along that has similar cluster requirements, mrjob will reuse the job flow.
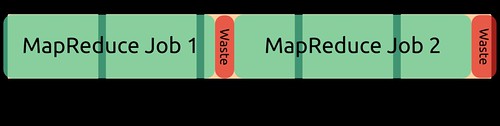
There are a few subtleties in implementing this: 1) what does it mean to have “similar cluster requirements”, 2) how to avoid race conditions between multiple jobs, and 3) when is the cluster finally shut down?
Similar job flows are defined meeting the criteria:
- Same Amazon Machine Image (AMI) version
- Same Hadoop version
- Same mrjob version
- Same bootstrap steps (bootstrap steps can set Hadoop or cluster options)
- Same or greater RAM and Compute Units for each node type (eg. Hadoop master vs workers)
- Accepts new jobs (job flows handle a max of 256 steps)
Race conditions are avoided by using locking. Locking is implemented using S3 in the regions that support consistency, US West by default. Jobs write to a specific S3 key with information about the job name and cluster type. Locks may timeout in the case of failures, which allow other jobs or the job terminator to reclaim the job flow.
Job flow termination is handled by a cron job which runs every 5 minutes, checks for idle job flows that are about to hit their hourly charge, and terminates them. This ensures that the worst case, never sharing job flows, is no more costly than the default.
To further improve utilization of job flows, jobs can wait a predetermined amount of time to find a job flow it can re-use. For example, for development jobs, mrjobs will try to find free job flows for 30 seconds before starting a new one. In production, jobs that don’t have strict deadlines could set the wait time to several hours.
We estimate around a 10% cost savings from using job flow pooling. From a developer’s perspective, this cost saving has come almost for free: by setting a few config settings, these changes went into effect without any action from developers. In fact, we saw a side benefit: iterative development of jobs was sped up significantly since subsequent runs of a modified MapReduce job could reuse a cluster and the cluster startup time was eliminated.
Reserved Instances
While AWS charges per machine hour by default, it offers a few other purchasing options that can reduce cost. Reserved instances are one of the more straightforward options: pay money upfront to receive a lower per-hour cost. When comparing AWS prices to buying servers, I encourage people to investigate this option: it is a more fair comparison to the capital costs and commitments of buying servers.
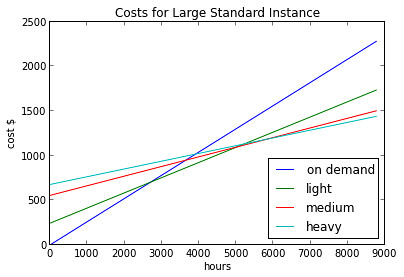
When is it cheaper overall to buy a reserved instance? It depends on how many hours an instance is used in a year. The plot above shows the cost of running a large standard instance with the different reserve instance pricing options: light, medium, or heavy usage. You can pay the on demand price, $0.26/hour, but after around 3000 hours (4 months) it becomes cheaper to cough up the $243 reserve price and only pay $0.17/hour for light usage of a reserved instance. Using more than 3000 hours per year? Then its time to investigate the increased usage plans, with “heavy” being the largest upfront, but lowest per-hour plan.
How many reserved instances should your company purchase? It depends on your usage. Rather than try to predict how much we will be using, we wrote a tool that analyzes past usage and recommends a purchasing plan that would have saved us the most money. The assumption is that our future usage will look similar to our past usage, and that the extra work and risk of forecasting was not worth the relatively small amount of money it would save. The tool is call EMRio and we open sourced it last year. It analyzes usage of EMR and recommends how many reserved instances to buy, as well as generates some pretty graphs.
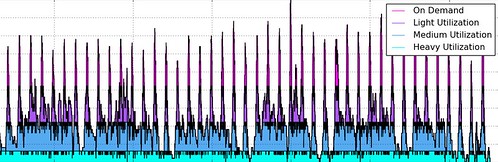
It’s important to note that reserved instance pricing is a billing construct. That is, you are not physically reserving a machine. At the end of the month, Amazon simply looks at how many instance hours you’ve used and applies the reserved instance rates to any instances that were running, up to the number of instances purchased.
Lessons Learned
Understand the trade-offs when moving to a cloud solution. For Yelp, the primary benefit of using AWS has been multiplying developer productivity by decreasing coordination costs and feature latency. Coordination costs come from requiring product teams to forecast and request resources from the system team. Purchasing resources, be it racks of servers or network capacity, can take weeks and increases the latency of feature launches. Latency has its own associated costs of decreased moral (great developers love shipping products) and context switching between projects. The dollar cost of AWS may be higher than a fully utilized, customized in-house solution, but the idea is you’ve bought much more productivity.
Focus on big wins: Incremental adoption of cloud technology is possible -- we’re doing it! Yelp started with EMR because it was our biggest win. Offline processing has spiky load characteristics, often does not require coordination between teams, and makes developers much more productive by providing leverage to their experiments. To best use the cloud, focus on solving your worst bottlenecks one at a time.
Build on abstractions: Don’t spin everyone up on all the details of a cloud service, just like you don’t spin everyone up on the details of your datacenter. Remember your trade-offs: the goal is to make developers much more productive, not be buzzword compliant. Having a scalable, adaptive infrastructure doesn’t matter if developers can’t use it as easily as they would a local script. Our favorite abstraction is mrjob, which lets us write and run MapReduce jobs in Python. Running a job on a local machine vs an EMR cluster is a matter of changing two command line arguments.
Establish policies and integration plans: Spinning up a single instance is easy, but when do you spin down a machine? Processing a day’s worth of logs is straightfoward, but how do you reliably transfer logs to S3? Have a plan for all of the supporting engineering that goes into making a system work: data integration, testing, backups, monitoring, and alerting. Yelp has policies around PII, separates production environments from development, and uses tools from the mrjob package to watch for run-away clusters.
Optimize after stability. There are many ways you can cut costs, but most of them require some complexity and future inflexibility. Make sure you have a working, abstracted solution before pursuing them so you can evaluate ROI. Yelp wrote EMRio after we had several months of data on EMR usage with mrjob. Trying to optimize before seeing how we actually used EMR would have been shooting in the dark.
Evaluating ROI: with some optimizations, cost evaluation is straightforward: how much would we have saved if we both reserved instances 2 months ago? Some are more difficult: what are the bottlenecks in the development process and can a cloud solution remove them? Easy or difficult, though, it is important to evaluate them before going into action. Profile code before optimizing it I assume you meant? If not I'd love to check out this profiler you're using :)
Future Directions
As Yelp grows its service oriented architecture, we are running into similar bottlenecks encountered for offline batch processing: coordination of resources, testing ideas, forecasting usage before launching new features. Therefore we’re again looking at the cloud to provide big wins for services like ad selection, search, and data ingestion. Look forward to future posts on the Yelp engineering blog about leveraging Asgard to build and deploy services, evaluating Python frameworks to serve RESTful APIs, and building abstractions to make it all easy to use. Of course, if you’d like to help build this future, let us know!



