Making the Case for Building Scalable Stateful Services in the Modern Era

For a long time now stateless services have been the royal road to scalability. Nearly every treatise on scalability declares statelessness as the best practices approved method for building scalable systems. A stateless architecture is easy to scale horizontally and only requires simple round-robin load balancing.
What’s not to love? Perhaps the increased latency from the roundtrips to the database. Or maybe the complexity of the caching layer required to hide database latency problems. Or even the troublesome consistency issues.
But what of stateful services? Isn’t preserving identity by shipping functions to data instead of shipping data to functions a better approach? It often is, but we don’t hear much about how to build stateful services. In fact, do a search and there’s very little in the way of a systematic approach to building stateful services. Wikipedia doesn’t even have an entry for stateful service.
Caitie McCaffrey, Tech Lead for Observability at Twitter, is fixing all that with a refreshing talk she gave at the Strange Loop conference on Building Scalable Stateful Services (slides).
Refreshing because I’ve never quite heard of building stateful services in the way Caitie talks about building them. You’ll recognize most of the ideas--Sticky Sessions, Data Shipping Paradigm, Function Shipping Paradigm, Data Locality, CAP, Cluster Membership, Gossip Protocols, Consistent Hashing, DHT---but she weaves them around the theme of building stateful services in a most compelling way.
The highlight of the talk for me is when Caitie ties the whole talk together around the discussion of her experiences developing Halo 4 using Microsoft’s Orleans on top of Azure. Orleans doesn’t get enough coverage. It’s based on an inherently stateful distributed virtual Actor model; a highly available Gossip Protocol is used for cluster membership; and a two tier system of Consistent Hashing plus a Distributed Hash Table is used for work distribution. With this approach Orleans can rebalance a cluster when a node fails, or capacity is added/contracted, or a node becomes hot. The result is Halo was able to run a stateful Orleans cluster in production at 90-95% CPU utilization across the cluster.
Orleans isn't the only example system covered. Facebook's Scuba and Uber's Ringpop are also analyzed using Caitie's stateful architecture framework. There's also a very interesting section on how Facebook cleverly implements fast database restarts for large in-memory databases by decoupling the memory lifetime from the process lifetime.
So let’s jump in and learn how to build stateful services...
Stateless Services are Wasteful
-
Stateless services have worked well. Storing the canonical source of truth in the database and horizontally scaling by adding new stateless service instances as needed has been very effective.
-
The problem is our applications do have state and we are hitting limits where one database doesn’t cut it anymore. In response we’re sharding relational databases or using NoSQL databases. This gives up strong consistency which causes part of the database abstraction to leak into services.
-
Data Shipping Paradigm
-
A client makes a service request. The service talks to the database and the database replies with some data. The service does some computation. A reply is sent to the client. And then the data disappears from the service.
-
The next request will be load balanced to a different machine and the whole process happens all over again.
-
-
It’s wasteful to repeatedly pull resources into load balanced services for applications that involve chatty clients operating over a session over a period of time. Examples: games, ordering a product, any application where you are updating information about yourself.
Stateful Services are Easier to Program
-
Caveat: stateful services are not magic. Stateless services are still incredibly effective if horizontal scalability is a requirement. Yet stateful services do offer a lot of of benefits.
-
Data Locality. The idea that requests are shipped to the machine holding the data that it needs to operate on. Benefits:
-
Low latency. Don’t have to hit the database for every single request. The database only needs to be accessed if the data falls out of memory. The number of network accesses is reduced.
-
Data intensive applications. If a client needs to operate a bunch of data it will all be accessible so a response can be returned quickly.
-
-
Function Shipping Paradigm
-
A client makes a request or starts a session the database is accessed one time to get the data and the data then moves into the service.
-
Once the request has been handled the data is left on the service. The next time the client makes a request the request is routed to the same machine so it can operate on data that’s already in memory.
-
Avoided are extra trips to the database which reduces latency. Even if the database is down the request can be handled.
-
-
Statefulness leads to more highly available and stronger consistency models.
-
In the CAP world where we have different levels of consistency that we operate against, some are more available than others. When there’s a partition CP systems chose consistency over availability and AP systems chose availability over consistency.
-
If we want to have more highly available systems under AP we get Write From Read, Monotonic Read, Monotonic Write. (for definitions)
-
If we have sticky connections where the data for a single user is on a single machine then you can have stronger consistency guarantees like Read Your Writes, Pipelined Random Access Memory.
-
Werner Vogel 2007: Whether or not read-your-write, session and monotonic consistency can be achieved depends in general on the "stickiness" of clients to the server that executes the distributed protocol for them. If this is the same server every time than it is relatively easy to guarantee read-your-writes and monotonic reads. This makes it slightly harder to manage load balancing and fault-tolerance, but it is a simple solution. Using sessions, which are sticky, makes this explicit and provides an exposure level that clients can reason about.
-
Sticky connections give clients an easier model to reason about. Instead of worrying about data being pulled into lots of different machines and having to worry about concurrency, you just have the client talking to the same server, which is easier to think about and is a big help when programming distributed systems.
-
Building Sticky Connections
-
A client makes a request to a cluster of servers and the request is always routed to the same machine.
-
Simplest way is to open up a persistent HTTP connection or a TCP connection.
-
Easy to implement because a connection means you are always talking to the same machine.
-
Problem: Once the connection breaks the stickiness is gone and the next request will be load balanced to another server.
-
Problem: load balancing. There’s an implicit assumption that all the sticky sessions last for about the same amount of time and generating about the same amount of load. This is not generally the case. It’s easy to overwhelm a single server with too many connections if they dog pile onto a server, if connections last a long time, or a lot of work is done for each connection.
-
Backpressure must be implemented so a server can break connections when they are overwhelmed. This causes the client to reconnect to a hopefully less burdened server. You can also load balance based on the amount of resources free to spread work out more equitably.
-
-
Something a little smarter is to implement routing in a cluster. A client can talk to any server in a cluster which routes the client to the server containing the correct data. Two capabilities are required:
-
Cluster membership. Who is in my cluster? How do we determine what machines are available to talk to?
-
Work distribution. How is load distributed across the cluster?
-
Cluster Membership
There are three general types of cluster membership systems: Static, Gossip Protocols, Consensus Systems.
Static Cluster Membership - The Simplest Approach
It’s OK to start with the dumbest thing possible and see if it meets your needs.
The simplest approach is a config file that contains all the addresses of the nodes in the cluster. The config file is distributed out to each machine.
Easy to do but operationally painful.
Not a great choice for services that have to be highly available.
It’s not fault tolerant. If a machine fails it must be replaced and the configuration updated.
It’s difficult to expand a cluster. To add machines the entire cluster must be restarted so work can be rebalanced correctly across the cluster.
Dynamic Cluster Membership
Nodes can be added or removed on the fly from the cluster.
To add capacity or to compensate failure, nodes can be added to the cluster and immediately start accepting load. Capacity can also be reduced by removing nodes.
Two main ways to handle cluster membership: gossip protocols and consensus systems.
Gossip Protocols - Emphasise Availability
Gossip protocols spread knowledge through the group by sending messages.
The messages talk about who they can talk to and who’s alive and who’s dead. Each machine on its own will figure out from the data it collects its world view of who is in the cluster.
In a stable state all the machines in the cluster will converge on having the same world view of who is alive and dead.
In the case of network failures, network partitions, or when capacity is added or deleted, different machines in the cluster can have different worldviews of who is the cluster.
There’s a tradeoff. You have high availability because no coordination is necessary, every machine can make decisions based on its own worldview, but your code has to be able to handle the uncertainty of getting routed to different nodes during failures.
Consensus Systems - Emphasise Consistency
All nodes in the cluster will have the exact same worldview.
The consensus system controls the ownership of everyone in the cluster. When the configuration changes all the nodes update their worldview based on the consensus system that holds the true cluster membership.
Problem: if the consensus system is not available then nodes can’t route work because they don’t know who’s in the cluster.
Problem: it will be slower because coordination is added to the system.
If you need highly availability consensus systems are to be avoided unless they are really necessary..
Work Distribution
Work distribution refers to how work is moved throughout the cluster.
There are three types of work distribution systems: Random Placement, Consistent Hashing, Distributed Hash Tables.
Random Placement
Sounds dumb but it can be effective. It works in scenarios where there’s a lot of data and queries operating on a large amount of data that’s distributed around the cluster.
A write goes to any machine that has capacity.
A read requires querying every single machine in the cluster to get the data back.
This isn’t a sticky connection, but it is a stateful service. It’s a good way to build in-memory indexes and caches.
Consistent Hashing - Deterministic Placement
-
Deterministic placement of requests to a node based on a hash, perhaps the session ID, or user ID, depending on how the workload is to be partitioned.
-
As nodes get mapped to the cluster, requests are mapped to the ring, and you walk right to find the node that’s going to execute the request.
-
Databases like Cassandra often use this approach because of the deterministic placement.
-
Problem: hotspots.
-
A lot of requests can end up being hashed to the same node and that node is overwhelmed with the traffic. Or a node can be slow, perhaps a disk is going bad, and it is overwhelmed with even normal amounts of requests.
-
Consistent hashing doesn’t allow work to be moved as a way of cooling down the hotspots.
-
So you have to allocate enough space in your cluster to run with enough headroom to tolerate deterministic placement and the fact that work can’t be moved.
-
This additional capacity is an additional cost the must be absorbed even in the normal case.
-
Distributed Hash Table (DHT) - Non Deterministic placement
A hash is used to lookup in a distributed hash table to locate where the work should be sent to. The DHT holds references to nodes in the cluster.
This is nondeterministic because nothing is forcing work to go to a particular node. It’s easy to to remap a client so it goes to some other node if a node becomes unavailable or becomes too hot.
Three Example Stateful Services in the Real World
Facebook’s Scuba - Random Fanouts on Writes
Scuba is a fast scalable distributed in-memory database used for code regression and analysis, bug reporting, revenue, and performance debugging. (more info)
It has to be very fast and always available.
The thought is it uses static cluster membership, though this is not explicitly stated in the paper.
Scuba uses random fanouts on writes. On reads every single machine is queried. All the results are returned and composed by the machine that is running the query and the results are returned to the user.
In the real world machines are unavailable so queries are run with best effort availability. If not all the nodes are available queries return a result over the data that is available, along with statistics about what percentage of the data they processed. The user can decide if the results meet a high enough threshold for quality.
Sticky connections aren’t used, but the data is in-memory so the lookups are very fast.
Uber’s Ringpop - Gossip Protocol + Consistent Hashing
Ringpop is a node.js library implementing application-layer sharding. (more info)
Uber has the concept of a trip. To start a trip a user orders a car which requires the rider information and location information, data is updated during the trip throughout the ride, and the payment must be processed at the end of the trip.
It would be inefficient for each of these updates to be load balanced to a different stateless server every time. The data would constantly be persisted to the database and then pulled back in again. This introduces a lot of latency and extra load on the database.
The design implements routing logic so all the requests for a user can be directed to a single machine.
The Swim Gossip Protocol is used to maintain cluster membership. It’s an AP cluster membership protocol so it’s not guaranteed to be always correct. Availability was chosen over correctness because it’s more important that a user can always order a car.
Consistent hashing is used to route work throughout the cluster. This has the hot node problem and the only remedy is to add more capacity, even if other nodes are under utilized.
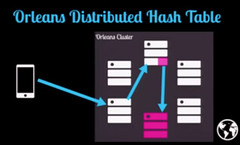
Microsoft’s Orleans - Gossip Protocol + Consistent Hashing + Distributed Hash Table
-
Orleans is a runtime and programming model for building distributed systems based on the Actor Model. (more info)
-
Orleans came out of Microsoft Research from the Extreme Computing Group. The presenter (Caitie McCaffrey) worked with the group to productize Orleans in the process of shipping Halo 4. All the Halo 4 services were rebuilt primarily on Orleans.
-
Actors are the core unit of computation. Actors communicate with each other using asynchronous messages throughout the cluster. When an Actor receives a message it can do one or more of the following: send one or more messages, update it’s internal state, create new Actors.
-
In a cluster based on the Actor model what you have is a bunch of state machines running, so the Actor model is inherently stateful if they are persisting state between requests.
-
In Halo 4 they would deploy a cluster of machines and Orleans took care of the rest.
-
A request would go to any machine in the cluster. The cluster would look up where the Actor lived in the cluster and route the message to the Actor.
-
Hundreds of thousands of Actors run on a single machine in the cluster.
-
A gossip protocol is used for cluster membership in order to be highly available. Since Orleans was open sourced a Zookeeper implementation was created, which is slower.
-
For work distribution Orleans uses a combination of consistent hashing + distributed hash tables.
-
When a request for an Actor is sent to the cluster the Orleans runtime will calculate a consistent hash on the Actor ID. The hash maps to a machine with a distributed hash table for that ID.
-
The distributed hash table for the Actor knows which machine contains the Actor for the specified ID.
-
After consulting the DHT, the request is routed to the appropriate machine.
-
-
Consistent hashing is used to find the Actor DHT, so it’s a deterministic operation. The location of the DHT in the cluster will not change. And since the amount of data in the DHT is small and the Actor DHTs are evenly distributed, hotspots are not a big concern.
-
What Actors are doing is not evenly distributed and balanced.
-
Orleans has the ability to automatically rebalance clusters. The entry in the DHT can be updated to point to a new machine when:
-
A session dies.
-
A machine failed so a new machined must be assigned.
-
An Actor was evicted from memory because nobody was talking to it.
-
A machine gets too hot so Orleans moves the Actor to a different machine with more capacity so the hot machine doesn’t fail.
-
-
The rebalancing feature of Orleans is a core reason why the Orleans cluster could be run in production at 90-95% CPU utilization across the cluster. Being able to move work around in a non-deterministic fashion means you can use all the capacity of a box.
-
This approach may not work for a database, but it does work great for pulling state into services.
What Can Go Wrong
Unbounded Data Structures
In stateful systems unbounded data structures are a good way to die. Examples: unbounded queues, unbounded in-memory structure.
It’s something we don’t have to think about often in stateless services because they can recover from these kind of transient failures.
In a stateful service a service can get a lot of requests so explicit bounds must be put on data structures or they may keep growing. Then you may run out of memory or your garbage collector may stop the world and the node may look dead (I would also add locks can be held for a long time as data structures grow).
Clients are not your friends. Clients won’t do what you want them to do. Machines can die because of the implicit assumption we won’t run out of memory or clients will only send a reasonable amount of data. Code must protect themselves against their clients.
Memory Management
-
Because data is being persisted in memory for the lifetime of a session, perhaps minutes, hours, or even days, memory will move into the longest lived generation of garbage collection. That memory is generally more expensive to collect, especially if there are references spanning generations.
-
You have to be more aware of how memory works in stateful services and you need to actually know how your garbage collector is running.
-
Or you could write everything in unmanaged code like C++, so you don’t have to deal with the garbage collector problem.
-
Orleans runs the .NET CLR, which is a garbage collected environment and they did run into cross generational garbage collection problems.
-
It was handled by tuning the garbage collector.
-
It was also handled by realizing a lot of unnecessary state was persisted. You have to be careful about what you are persisting because there is an associated cost.
-
Reloading State
Typically in a stateless service the database must be queried for each request so the latency must be tuned to account for the round trip to the database. Or you can use a cache to make it faster.
In a stateful service there are a variety of different times state can be reloaded: first connection, recovering from crashes, deploying new code.
First Connection
Generally the most expensive connection because there is no data on the node. All the data must be pulled into the database so requests can be handled.
This could take a long time, so you want to be very careful what you load on startup. You don’t want a high latency hit for a request that just happens to land on the first connection.
In testing make use of percentiles. Your average latency will look good because you don’t have to round trip to the database every time. The first connection latency may spike and you don’t want to miss that.
On a first connection if the client times out because access to the database is slow you continue trying to load from the database because you know the client will retry again. The next access by the client will be fast because the data will likely be in memory. In a stateless service you can’t make this kind of optimization.
In Halo, for example, when a game started the first connection would sometimes timeout. Perhaps the user had a lot game state or the connection was loaded. So they kept pulling in the data in and when the gamebox retried the request would succeed. The latency wasn’t user noticeable, especially given the pretty animation the user was watching.
Recovering From Crashes
If you have to rehydrate an entire box after recovering from a crash that could be expensive if you are not lazily loading all the Actors. Sometimes you can get away with lazy loading and sometimes you can't.
Deploying New Code
To deploy new code you have to take down an entire box and bring it back up another box. It can be a problem if you don’t have non-deterministic placement or dynamic clustering membership.
Fast Database Restarts at Facebook
Facebook’s Scuba product had the restart problem because it was an in-memory database storing a lot of data that was persisted to hard disk.
On a crash or a deploy they would take down the machine that was currently running, spin up a new machine, then read everything from disk. This took hours per machine. And because of their SLAs Facebook had to do a slow rolling update of their cluster that took up to 12 hours.
A crash doesn’t happen all that often so a slow restart is not that big a concern. We would like code deploys to happen frequently so we can iterate faster, try new ideas, do less risky deployments.
Facebook made the key observation that you can decouple the memory lifetime from the process lifetime, especially in a stateful service.
When Facebook wanted to deploy new code, and they knew it was a safe shutdown and memory wasn’t corrupted, they would: stop taking requests, copy data from the currently running process to shared memory, shutdown the old process, bring up the new process, then the data from shared memory would be copied back into the process memory space, and then requests would restart.
This process takes minutes so a cluster restart is now in the order of two hours instead of 12 hours. Now it’s possible to deploy new code more frequently than was previously possible.
Twitter is considering implementing this strategy for a stateful index that when a whole machine is restarted has to talk to their Manhattan database, which is really slow compared to memory.
Wrapping Up
-
There’s a lot of work and thought that has to go into cluster membership and work distribution.
-
There’s no one right answer.
-
She leans to the available side so prefers Gossip protocols.
-
For work distribution it depends on the work load.
-
-
There are a bunch of successful stateful systems running in the real world. It’s proven that you can make this work at scale, so it’s not super scary though it is new ground.
-
Be cautious because this is new territory if you haven’t done stateful services before. Go through what is different, what has changed, what assumptions are you making, and make sure you make your assumptions explicit.
-
Read papers. Do not reinvent your own protocols. This actually not new territory. People have been working on it since the 60s and 70s. Most of this talk has come from database literature. These problems are already solved. You can cherry-pick what you care about based on your application. You don’t have to implement the whole paper, just implement the piece of the paper you want.
Related Articles
CaitieM.com is Caitie McCaffrey’s blog.
Halo 4: High Demand with Low Latency and High Availability
Orleans: A Framework for Cloud Computing
Architecting and Launching the Halo 4 Services
Why can't anyone launch an online service without outages?
#WindowsAzure Lessons Learned : Be Stateful
Creating scalable backends for games using open source Orleans framework



