MongoDB and GridFS for Inter and Intra Datacenter Data Replication

This is a guest post by Jeff Behl, VP Ops @ LogicMonitor. Jeff has been a bit herder for the last 20 years, architecting and overseeing the infrastructure for a number of SaaS based companies.
Data Replication for Disaster Recovery
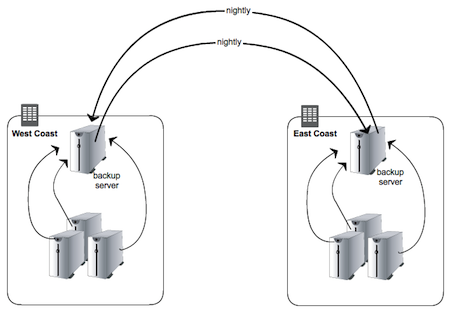
An inevitable part of disaster recovery planning is making sure customer data exists in multiple locations. In the case of LogicMonitor, a SaaS-based monitoring solution for physical, virtual, and cloud environments, we wanted copies of customer data files both within a data center and outside of it. The former was to protect against the loss of individual servers within a facility, and the latter for recovery in the event of the complete loss of a data center.
Where we were: Rsync
Like most everyone who starts off in a Linux environment, we used our trusty friend rsync to copy data around.
Rsync is tried, true and tested, and works well when the number of servers, the amount of data, and the number of files is not horrendous. When any of these are no longer the case, situations arise, and when the number of rsync jobs needed increases to more than a handful, one is inevitably faced with a number of issues:
- backup jobs overlapping
- backup job times increasing
- too many simultaneous jobs overloading servers or networks
- no easy way to coordinate additional steps needed after rsync job completion
- no easy way to monitor job counts, job statistics, and get alerted on failuresHere at LogicMonitor our philosophy and reason for being is rooted in the belief that everything in your infrastructure needs to be monitored, so the inability to easily monitor the status of rsync jobs was particularly vexing (and no, we do not believe that emailing job status is monitoring!). We needed to get better statistics and alerting, both in order to keep track of backup jobs, but also to be able to put some logic into the jobs themselves to prevent issues like too many running simultaneously.
The obvious solution was to store this information into a database. A database repository for backup job metadata, where jobs themselves can report their status, and where other backup components can get information in order to coordinate tasks such as removing old jobs, was clearly needed. It would also enable us to monitor backup job status via simple queries for information such as the number of jobs running (total, and on a per-server basis), the time since the last backup, the size of the backup jobs, etc., etc.
MongoDB as a Backup Job Metadata StoreThe type of backup job statistics was more than likely going to evolve over time, so MongoDB came to light with its “schemaless” document store design. It seemed the perfect fit: easy to setup, easy to query, schemaless, and a simple JSON style structure for storing job information. As an added bonus, MongoDB replication is excellent: it is robust and extremely easy to implement and maintain. Compared to MySQL, adding members to a MongoDB replica set is auto-magic.
So the first idea was to keep using rsync, but track the status of jobs in MongoDB. But it was a kludge to have to wrap all sorts of reporting and querying logic in scripts surrounding rsync. The backup job metainfo and the actual backed up files were still separate and decoupled, with the metadata in MongoDB and the backed up files residing on a disk on some system (not necessarily the same). How nice it would be if the the data and the database were combined. If I could query for a specific backup job, then use the same query language again for an actual backed up file and get it. If restoring data files was just a simple query away... Enter GridFS.
Why GridFSYou can read up on the details GridFS on the MongoDB site, but suffice it to say it is a simple file system overlay on top of MongoDB (files are simply chunked up and stored in the same manner that all documents are). Instead of having scripts surround rsync, our backup scripts store the data and the metadata at the same time and into the same place, so everything is easily queried.
And of course MongoDB replication works with GridFS, meaning backed up files are immediately replicated both within the data center and off-site. With a replica inside of Amazon EC2, snapshots can be taken to keep as many historical backups as desired. Our setup now looks like this:
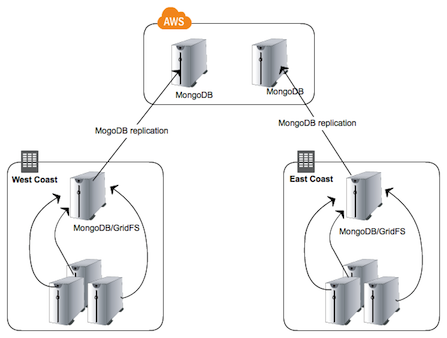
Advantages
- job status information available via simple queries
- backup jobs themselves (including files) can be retrieved and deleted via queries
- replication to off-site location is practically immediate
- sharding possible
- with EBS volumes, MongoDB backups (metadata AND actual backed up data) via snapshots is easy and limitless
- automated monitoring of status is easy
Monitoring via LogicMonitor
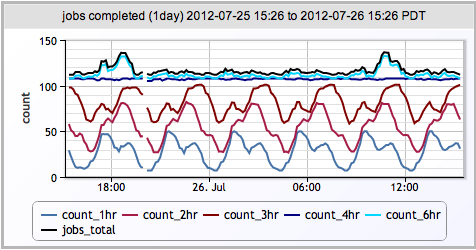
LogicMonitor believes all aspects of your infrastructure, ranging from physical to application level, should be in the same monitoring system: UPSs, chassis temperature, OS statistics, database statistics, load balancers, caching layers, JMX statistics, disk write latency, etc., etc. It should all be there, and this includes backups. To that end, LogicMonitor can not only monitor general MongoDB statistics and health, but also can execute arbitrary queries against MongoDB. These queries can be for anything from login statics to page views to (guess what?) backup jobs completed in the last hour. Now that our backups are all done via MongoDB, I can keep track of (and more importantly, be alerted on):
- number of backup jobs running per individual server
- number of backups being performed simultaneously amongst all servers
- any customer portal that has not been backed up for greater than 6 hours
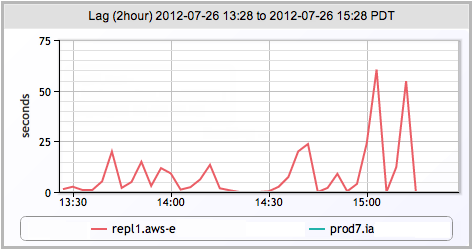
- MongoDB replication lag
Replication Lag
Jobs Completed