Scaling @ HelloFresh: API Gateway

HelloFresh keeps growing every single day: our product is always improving, new ideas are popping up from everywhere, our supply chain is being completely automated. All of this is simply amazing us, but of course this constant growth brings many technical challenges.
Today I’d like to take you on a small journey that we went through to accomplish a big migration in our infrastructure that would allow us to move forward in a faster, more dynamic, and more secure way.
The Challenge
We’ve recently built an API Gateway, and now we had the complex challenge of moving our main (monolithic) API behind it — ideally without downtime. This would enable us to create more microservices and easily hook them into our infrastructure without much effort.
The Architecture
Our gateway is on the frontline of our infrastructure. It receives thousands of request per day, and for that reason we chose Go when building it, because of its performance, simplicity, and elegant solution to concurrency.
We already had many things in place that made this transition more simple, some of them are:
Service Discovery and Client Side Load Balancing
We use consul as our service discovery tool. This together with HAProxy
enables us to solve two of the main problems when moving to a microservice architecture: service discovery (automatically registering new services as they come online) and client side load balancing (distributing requests across servers).
Automation
Maybe the most useful tool in our arsenal was the automation of our infrastructure. We use Ansible to provision anything in our cloud — this goes from a single machine to dealing with network, DNS, CI machines, and so on. Importantly, we’ve implemented a convention: when creating a new service, the first thing our engineers tackle is to create the Ansible scripts for this service.
Logging and Monitoring
I like to say that anything that goes in our infrastructure should be monitored somehow. We have some best practices in place on how to properly log and monitor your application.
- Dashboards around the office show how the system is performing at any given time.
- For logging we use the ELK Stack, which allows us to quickly analyze detailed data about a service’s behavior.
- For monitoring we love the combination of statsd + grafana. It is simply amazing what you can accomplish with this tool.
Grafana dashboards give amazing insight into your performance metrics
Understanding the current architecture
Even with all these tools in place we still have a hard problem to solve: understand the current architecture and how we can pull off a smooth migration. At this stage, we invested some time on refactoring our legacy applications to support our new gateway and authentication service that would be also introduced in this migration (watch this space for another article on that — Ed).
Some of the problems we found:
- While we can change our mobile apps, we have to assume people won’t update straight away. So we had to keep backwards compatibility — for example in our DNS — to ensure older versions didn’t stop working.
- We had to analyze all routes available in our public and private APIs and register them in the gateway in an automated way.
- We had to disable authentication from our main API and forward this responsibility to the auth service.
- Ensuring the security of the communication between the gateway and the microservices.
To solve the import problems we wrote a script (in Go, again) to read our OpenAPI specification (aka Swagger) and create a proxy with the correct rules (like rate limiting, quotas, CORS, etc) for each resource of our APIs.
To test the communication between the services we simply set up our whole infrastructure in a staging environment and started running our automated tests. I must say that this was the most helpful thing that we had during our migration process. We have a large suite of automated functional tests that helped us maintaining the same contract that the main API was returning to our mobile and web apps.
After we were quite sure that our setup worked on our staging environment we started to think about on how to move this to production.
The first attempt
Spoiler alert: our first attempt at going live was pretty much a disaster. Even though we had a quite nice plan in place we were definitely not ready to go live at that point. Let’s check the step by step of our initial plan:
- Deploy latest version of the API gateway to staging
- Deploy the main API with changes to staging
- Run the automated functional tests against staging
- Run manual QA tests on staging website and mobile apps
- Deploy latest version of the API gateway to live
- Deploy the main API with changes to live
- Run the automated functional tests against live
- Run manual QA tests on live website and mobile apps
- Beer
Everything went quite well on staging (at least according to our tests), but when we decided to go live we started to have some problems.
- Overload on the auth database: we underestimated the amount of requests we’d receive, causing our database to refuse connections
- Wrong CORS configuration: for some endpoints we configured the CORS rules incorrectly, causing requests from the browser to fail
Thanks to our database being flooded with requests we had to roll back right away. Luckily, our monitoring was able to catch that the problem occurred when requesting new tokens from the auth-service.
The second attempt
We knew that we didn’t prepare well for our first deploy, so the first thing we did right after rolling back was hold a post mortem. Here’s some of the things we improved before trying again:
- Prepare a blue-green deployment procedure. We created a replica of our live environment with the gateway deployed already, so all we needed to when the time came was make one configuration change to bring this cluster online. We could rollback if necessary with the same simple change.
- Gather more metrics from the current applications to help us have the correct machine sizes to handle the load. We used the data from the first attempt as a yardstick for the amount of traffic we expected, and ran load tests with Gatling to ensure we could comfortably accommodate that traffic.
- Fix known issues with our auth service before going live. These included a problem with case-sensitivity, a performance issue when signing a JWT, and (as always) adding more logging and monitoring.
It took us around a week to finish all those tasks, and when we were finished, our deployment went smoothly with no downtime. Even with the successful deployment we found some corner case problems that we didn’t cover on the automated tests, but we were able to fix them without a big impact on our applications.
The results
In the end, our architecture looked like this:
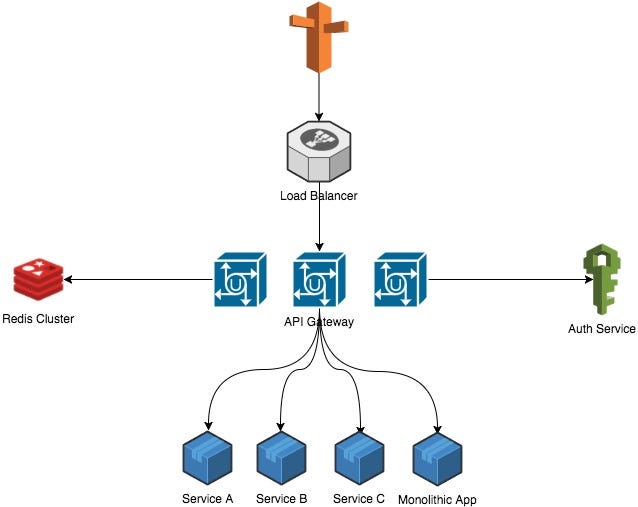
API Gateway Architecture
Main API
- 10+ main API servers on High-CPU Large machines
- MySQL instances run in a master-replica setup (3 replicas)
Auth service
- 4 application servers
- PostgreSQL instances run in a master-replica setup (2 replicas)
- A RabbitMQ cluster is used to asynchronously handle user updates
API Gateway
- 4 application servers
- MongoDB instances run in a master-replica setup (4 replicas)
Miscellaneous
- Ansible is used to execute commands in parallel on all machines. A deploy takes only seconds
- Amazon CloudFront as the CDN/WAF
- Consul + HAProxy as service discovery and client side load balancing
- Statsd + Grafana to graph metrics across the system and alert on problems
- ELK Stack for centralizing logs across different services
- Concourse CI as our Continuous Integration tool
I hope you’ve enjoyed our little journey, stay tuned for our next article.



