Scaling indexing and search - Algolia New Search Architecture Part 2


What would a totally new search engine architecture look like? Who better than Julien Lemoine, Co-founder & CTO of Algolia, to describe what the future of search will look like. This is the second article in a series. Here's Part 1.
Search engines need to support fast scaling for both Read and Write operations. Rapid scaling is essential in most use cases. For example, adding a vendor in a marketplace generates a spike of indexing operations (Write), and a marketing campaign generates a spike of queries (Read). In most use cases, both Read and Write operations scale but not at the exact same moment. The architecture needs to handle efficiently all these situations as the scaling of Read and Write operations varies over time in most use cases.
Until now, search engines were scaling with Read and Write operations colocated on the same VMs. This scaling method brings drawbacks, such asWrite operations unnecessarily hurting the Read performance and using a significant amount of duplicated CPU at indexing. This article explains those drawbacks and introduces a new way to scale more quickly and efficiently by splitting Read and Write operations.
1. Anatomy of an index
Search engines have a lot in common with relational databases, but they represent data differently. Search engines store flattened objects instead of inter-connected tables. For example, the relational database would store a product via several linked tables in an eCommerce use case. Figure 1 shows an example of a simple product stored in an eCommerce platform.

Figure 1. Example of database tables to store a product in an eCommerce platform
Compared to a database, a search engine flattens a product, placing all the properties in a single record. So in the previous example, the search engine would use two different objects: one object containing all the information in English inside the products_en index (Figure 2), and one object containing all the Chinese information inside the products_cn index (Figure 3).
This flattened representation allows search engines to split the index into several independent data sets. One object, which contains all the required information, can be located in only one of those data sets. This property allows a search engine to represent one index as N smaller independent databases (we call each of them a shard). This model allows parallelization of the majority of read and write operations for better performance.
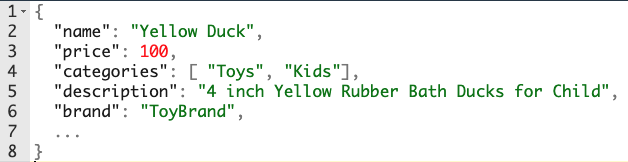
Figure 2. Example of the English version of the product in JSON before ingestion by a search engine

Figure 3. Example of the Chinese version of the product in JSON before ingestion by a search engine
To understand how search engines scale, it’s necessary to know about all the CPUs involved in the indexing phase. In a search engine, there’s a lot of data processing before updating data structures. Each record will be processed to recognize words/entities/categories. For example, we use a machine learning model to identify the words in Chinese as there are no separators between words. Each word will update an inverted-list data structure. Some search engines also pre-compute all the static parts of the ranking formula during indexing to optimize the search performance. The indexing CPU can become even more expensive when the search engine also computes a vector-based index, typical for semantic indexing or image indexing. This means that we need to distribute the indexing CPU in a search engine as it can become a bottleneck that will slow down the whole indexing process.
2. Standard scaling pattern
Most relational databases and search engine architectures share a typical pattern to support more Read operations. To support more queries, we introduce different copies of data. For example, suppose we have three copies of the data on three servers. In this case, we can process three times more queries than with only one copy on one server. To support more Write operations, we split the data into several smaller pieces called shards and added more CPUs to build these shards. Scaling both Read and Write operations requires adding shards and having several copies across several machines.
The main mechanism to implement this logic is via a primary/replicas architecture, which replicates the data of the primary over several replicas. To replicate the data, the system will need each shard to have one version accepting Write operations (the primary). All the other versions of the shard (the N replicas) use the primary shard as the source of truth. The mechanism used to sync the data between the primary and the replicas is often a LOG file stored on the primary shard; this LOG file contains all the Write operations accepted by the primary shard in sequential order. Each replica shard reads the Write operations from this LOG and applies them locally. Figure 4 shows this link on an index with four shards, each having two replicas.
The main disadvantage of this approach is colocating the indexing and search on the same machine. It means we duplicate the indexing CPU and memory as we need to build several copies of the data. The additional CPU and memory add significant overhead when you only need to scale the read operations, because the duplication factor increases. It becomes prohibitive when you need to simultaneously scale the indexing and searches, as the replication factor increases and is applied to a bigger volume of data.
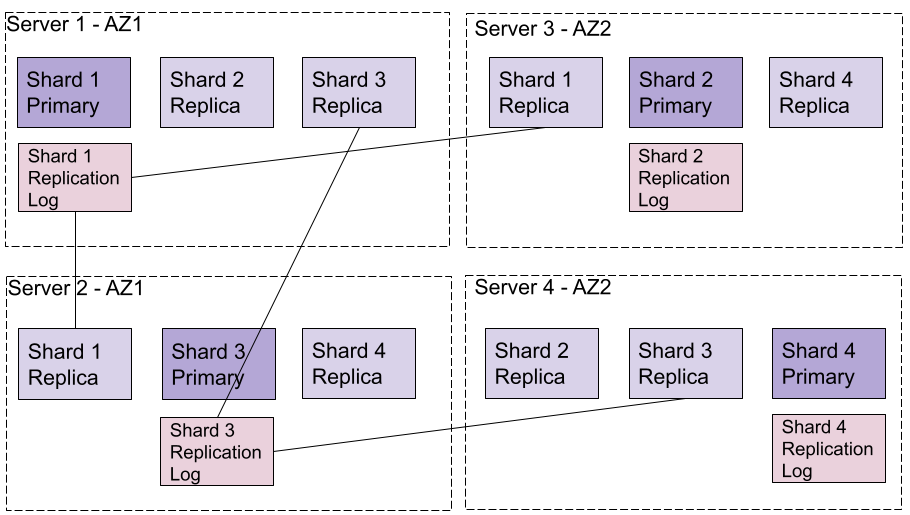
Figure 4. Example of an index with four shards described across four servers. Each replica is connected to the primary replication log (only shard 1 and shard 3 are represented for readability).
The indexing CPU and memory resources can also negatively impact the end-user experience when the same machine processes indexing operations and search queries. When there is a spike in search traffic generated by end-users, the resources used for indexing can limit the ability to honor this spike of traffic.
Algolia's first architecture reduced this problem by splitting the indexing and the searches into two different processes. We used one Linux kernel functionality to prioritize the process handling searches compared to the indexing operation by setting different Nice Values. This prioritization was a good workaround, but it was still not optimal. Supporting a higher volume of queries requires new replicas and duplicating all the CPU and memory used for indexing.
Another significant drawback to this approach is that it limits the ability to auto-scale. Adding a new replica requires fetching the data from existing machines and replay the LOG; this often takes several hours and adds additional load on machines already at their limits. Adding more resources to build the shards also requires moving the shards between machines, with the same drawback. The consequence is that you have to significantly over-size your architecture, and anticipate the significant increase of data or queries. All architectures that perform the indexing operations on the same machine as the search operations have this issue.
3. Another way to scale
There is an alternative to replication. Instead of replicating the indexing operations coming from the user, we can replicate the binary data structure committed on the disk after the indexing task.
The main advantage of this approach is that it avoids duplicating the CPU and memory used for indexing. The main disadvantage is that it introduces some latency as the binary files can be large when the optimization operation rewrites all the data structures.
Search engine architectures often handle a large volume of indexing operations and searches while targeting a sub-minute indexing speed. This is why most actors did not use this approach. Also, search engines rely on generational data structures. In practice, it means that there is a set of files instead of having one binary file representing a shard on a disk. The implementation is often similar to a Log Structured Merge Tree (LSM Tree) applied to the whole shard (inverted lists, objects store, etc.). When the shard receives new indexing operations, it’s stored on a smaller data structure on a disk. Figure 5 illustrates a simple LSM Tree with only two levels applied to two shards. The new indexing operations are performed on level 0 until the shards reach a specific size and need to be merged with level 1.
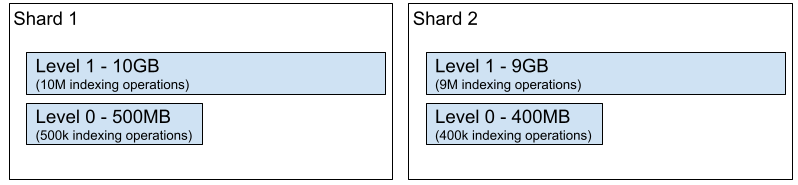
Figure 5. Simplified example of a data structure representing two shards with two levels
Such a merge operation is required to remove duplicates and optimize search efficiency (each query needs to be done on each level and merged). The drawback is that all the files on disk change, and each replica needs to fetch the new version containing all the shard data.
Figure 6 illustrates the volume of data transferred to replicas over time when shard 1 of figure 5 received a constant flow of 1000 update operations per minute. Every minute, 1000 indexing operations update the existing records in the shard. We transfer the updated level 0 file to replicas until we trigger a merge of level 0 with level 1 (reached when level 0 reaches 1GB). This merge happens a bit after 8 am and results in the transfer of the new level 0 file (10GB) to the replica.

Figure 6. Illustration of the impact of merging the data to transfer for replication
Many factors will impact such a graph. The two most important are:
The shard size. This size defines the maximum volume of data to transfer after a merge of all levels.
The number of levels in the LSM tree. It will directly affect the frequency of the merge of all levels (the number of times we have to transfer the maximum data size).
When you have the best shard size for your setup, and the appropriate number of levels in your tree, the remaining problem is a network and disk problem. How can you reduce the indexing latency on the replicas to target sub-minute latency?
4. Introducing fast files replication
The good news is that cloud infrastructure evolved dramatically in the last decade leading to a new world where we have access to enormous bandwidth (up to 100Gbps interface). Those evolutions allow strong isolation between indexing and search without having the negative impact of the indexing delay. This isolation leads to a more efficient and dynamic scaling.
Figure 7 illustrates how to leverage a Cloud storage infrastructure to build one shard. The same logic allows building N shards in parallel. The architecture contains the following components:
The indexing VM has a copy of the file locally on SSD. In case of hardware failure, a new machine is launched and fetches a copy from Cloud storage.
New files are computed in memory by the indexing process.
Files are uploaded using a multipart upload. Every large file is pushed in parallel to the Cloud storage (we split files into N small segments).
In parallel to uploading to the Cloud storage, files are stored locally on the disk of the indexing VM (as a cache).
When the push is finalized, the search VM fetches all the files using the multipart download.
The search process switches to this new version of the data when all the files are in memory.
Optionally, if the Search VM is configured to have less memory than the data, the data is also copied on the local disk.

Figure 7. View of one shard stored on Cloud storage with a different VM for indexing and search
The main advantages of this approach are:
You can reduce the impact of the merge to under a minute via a multipart upload for shards. You can even target near-real-time indexing by reducing the shard size, for example, by selecting a shard size of 1GB.
Searches operations and indexing operations scale independently. They both have dedicated virtual machines.
Indexing latency can be reduced to under a minute when the shards are not exceeding a few gigabytes.
Adding/Removing a new Search VM can be very fast (under a minute if the shard is a few gigabytes).
Adding/Removing a new Indexing VM or replacing one with more cores is also very fast. Replacing one VM building twenty shards of 1GB by two VMs building ten shards can be achieved in under a minute.
This different architecture allows adding and/or removing resources without a long and expensive rebalancing of the data. This architecture also allows new types of functionality like changing the number of shards for one index via an asynchronous process without pausing the indexing.
Cloud storage is responsible for the High Availability of indexing with a factor three replication. The Indexing VM can die; it will be replaced by another VM that will fetch the previous data version from Cloud storage. High Availability of search is achieved by having different Search VMs spread across different availability zones. Another attractive property of Cloud storage is that the data is replicated in several regions; this simplifies a cross-region deployment. You only need to have the Search VM in different regions.
Final thoughts
With this architecture, we have strong isolation of Read and Write operations, which allows us to scale them independently and introduce dynamic scaling. There is no more need to anticipate a significant increase in traffic or indexing, or massively over-sizing the setup. This architecture is not limited to inverted-lists indexing; it also works for a vector search engine and any architecture with strong independence between the shards.



