Viddler Architecture - 7 Million Embeds a Day and 1500 Req/Sec Peak


Viddler is in the high quality Video as a Service business for a customer who wants to pay a fixed cost, be done with it, and just have it work. Similar to Blip and Ooyala, more focussed on business than YouTube. They serve thousands of business customers, including high traffic websites like FailBlog, Engadget, and Gawker.
Viddler is a good case to learn from because they are a small company trying to provide a challenging service in a crowded field. We are catching them just as they transitioning from a startup that began in one direction, as a YouTube competitor, and pivoted into a slightly larger company focussed on paying business customers.
Transition is the key word for Viddler: transitioning from a free YouTube clone to a high quality paid service. Transitioning from a few colo sites that didn't work well to a new higher quality datacenter. Transitioning from an architecture that was typical of a startup to one that features redundancy, high availability, and automation. Transitioning from a lot of experiments to figuring out how they want to do things and making that happen. Transition to an architecture where features were spread out amongst geographically distributed teams using different technology stacks to having clear defined roles.
In other words, Viddler is like most every other maturing startup out there and that's fun to watch. Todd Troxell, Systems Architect at Viddler, was kind enough to give us an interview and share the details on Viddler's architecture. It's an interesting mix of different technologies, groups, and processes, but it somehow seems to all work. It works because behind all the moving parts is the single idea: making the customer happy and giving them what they want, no matter what. That's not always pretty, but it does get results.
Site: Viddler.com
The Stats
- About 7 million embed views per day.
- About 3000 videos uploaded per day.
- 1500 req/sec at peak.
- ~130 people pressing the play button at peak.
- 1PB of video served in February
- 80T of storage
- 45,160 hours of CPU time spent on video encoding in last 30 days
- Usage is relatively flat throughout the day, with only a ~33% difference between valley and peak which suggests they get a lot of usage globally. graphic.
The Platform
Software
- Debian Linux
- Rails 2.x- dashboard, root page, contest manager, various subfeatures
- PHP - various legacy subsites that use our internal APIs
- Python/ffmpeg/mencoder/x264lib - video transcoding
- Java 1.6 / Spring / Hibernate / ehcache- API and core backend
- Mysql 5.0 - main database
- Munin, Nagios, Catchpoint - monitoring
- Python, Perl, and ruby - many *many* monitors, scripts
- Erlang - ftp.viddler.com
- Apache 2/mod_jk - core headend for backend Java application
- Apache /mod_dav - video storage
- Amazon S3 - video storage
- Amazon EC2 - upload and encoding
- KVM - virtualization for staging environment
- Hadoop HDFS - distributed video source storage
- Nginx/Keepalived - Load balancers for all web traffic
- Wowza - RTMP video recording server
- Mediainfo - reporting video metadata
- Yamdi - metadata injector for flash videos
- Puppet - configuration management
- Git/Github https://github.com/viddler/
- Logcheck - log scanning
- Duplicity - backup
- Trac - bug tracking
- Monit - process state monitoring / restarting
- iptables - for firewalling - no need for hardware firewall - also handles NAT for internal network.
- maatkit, mtop, xtrabackup - db management and backup
- Preboot eXecution Environment - network boot of computers.
- Considering OpenStack's Swift as alternative file store.
- FFmpeg - a complete, cross-platform solution to record, convert and stream audio and video.
- Apache Tomcat
- MEncoder - a free command line video decoding, encoding and filtering tool.
- EdgeCast - CDN
Hardware
- 20+ nodes in total in their colo:
- 2 Nginx load balancers.
- 2 Apache servers.
- 8 Java servers run the API.
- 2 PHP/Rails servers run the front-end.
- 3 HDFS servers
- 1 Monitoring server.
- 1 Local encoding server.
- 2 storage servers.
- 2 MySQL database servers run in master-slave configuration, plan on moving to 6 servers.
- 1 staging server.
- Amazon servers are used for video encoding.
The Product
Sign up for a Viddler account and they'll translate your video to whatever format is needed and it will display on any device. They provide an embed code, dashboard, and analytics. Their goal is to wrap up the problem of video behind a simple interface so people can just buy the service and forget about it, it just works and does everything you need it to do. As a content provider you can sell views and add ads to content. They bring all ad networks into Viddler as kind of meta interface to do different ad platforms.
The Architecture
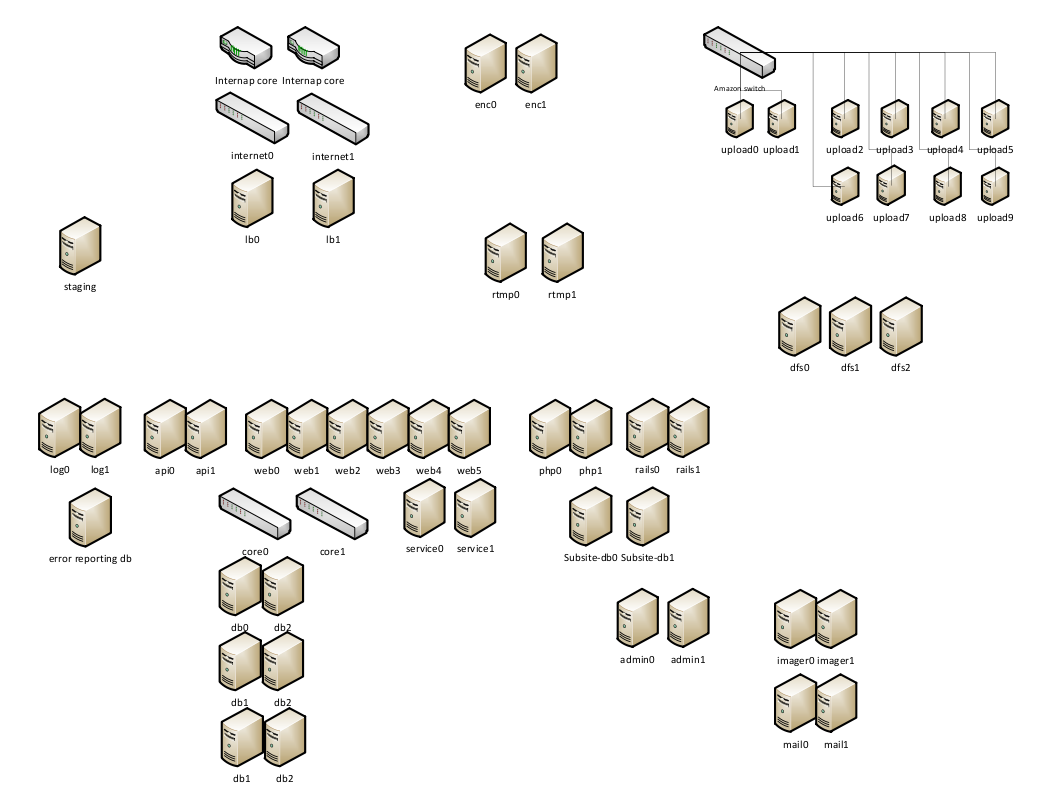
- The Current Era
- Their current system runs on bare metal in a colo somewhere in the Western US. They are in the process of moving to Internap in New York.
- A 1 gbps link connects them to the Internet. A CDN serves video and the video is loaded directly into Amazon for processing, so they don't need more network than this for their main site.
- The system is fronted by 2 Nginix load balancers, one active and the other passive using keepalived. Chose Nginix because it is Linux based, Open Source, and it worked.
- EdgeCast is used as the CDN to distribute content. Customers upload video directly to Amazon, the video is processed and uploaded to the CDN.
- Nginx can failover to the two Apache servers. The Apache servers can failover to one of the backend servers running Tomcat.
- Part of their architecture runs in Amazon: storage and their upload and encoding services.
- Experimented with Cassandra for storing dashboard positions. Very reliable, but will probably move to MySQL in the future.
- Two image scaling nodes at Linode for creating arbitrary thumbnails for videos. That will move to New York in the future.
- The Very Soon Era at Internap
- Original idea for the site was a free video site, YouTube but better. Then they pivoted to be more of high quality service which dictates the need for a better more reliable infrastructure.
- They are in the process of moving to Internap, so not everything has been worked out yet. Some issues in their previous datacenter motivated the move:
- Network issues, some BGP (Border Gateway Protocol) providers would stop working, they wouldn't peer automatically, and they would end up with a dead site for an hour and had to really push to have their datacenter manually remove the peer.
- They were subleased to a provider who kicked them out which meant they had to move two racks of servers with little lead time.
- Internap is well known for their good network, it's a better facility, and is more reliable.
- A major goal is to have complete redundancy in their architecture. Doubling the number of RTMP servers, dedicated error recording system, doubling monitoring servers, splitting out PHP and Rails servers, add dedicated image scaling servers, and double the number of encoding servers.
- Another major goal is complete automation. They will pixie boot computers over the network, get an OS on it, and configure packages from CVS. Currently their system is unreproducable and they would like to change that.
- Experimenting with HDFS as a file store for videos. They store 10% of their videos, about 20TB, on 3 HDFS nodes, and it has never been down.
- Current goal it to get everything moved over, the entire system to be autobuilt, and in version control, make sure ops guys are hired and to have a schedule.
- Observation that they are in a similar business to Amazon in that it's a lot cheaper to do everything yourself in the Video world, but then you have to do everything yourself.
- No plans to use a service architecture. They have an internal API and external API. Both are used create the site. There are higher reward features to implement than changing over to a service approach.
- Automation will transform everything.
- Portable VMs will allow them to reproduce build environments and live environments. Currently these are not reproducible. Everyone develops on their own OS using different versions of packages.
- Will allow them to iterate on architecture. Try new storage, etc by just downloading a new VM to run against.
- Make any transition to OpenStack less painful. Considering VMware as well.
- When you upload to Viddler the endpoint is on Amazon EC2 on a node running Tomcat.
- The file is buffered locally and sent to S3.
- The file is the pulled down from S3 for encoding.
- The encoding process has its own queue in a module called Viddler Core.
- They segregate out code the runs in their colo site and code that runs in Amazon. The code that runs in Amazon doesn't maintain state. A spawned node can die because all the state is kept in S3 or Viddler Core.
- A Python encoding daemon pulls work off the queue:
- Runs FFmpeg, MEncoder, and other encoders.
- There's lots of funky stuff about checking if iPhone video needs rotating before encoding and other tests.
- Each encoding node runs on an Amazon 8 core instance. Four encodings run at a time. They haven't tried to optimize this yet.
- Jobs are run in priority order. A live upload that someone wants to see right away will be handled before a batch job of say adding iPhone support to their encodes.
- Python daemons are long running daemons and they haven't see any problems with memory fragmentation or other issues.
- Exploring real-time transcode.
- In real-time encoding a node instance is fed like a multi-part form, streams it through FFmpeg, and then streams it out again. This could be part of their CDN.
- The biggest advantage of this architecture is there is no wait. Once a customer has uploaded a video it's live.
- The implication is only one video format of a file would need to be stored. It could transcoded on demand to the CDN. This could save the customer a lot of money in storage costs.
- Storage costs:
- CDN and storage are their biggest costs. Storage is about 30% of their costs.
- The average case for people who want their video to play on everything is four formats. HTTP streaming will be another format. So storage cost is a major expense for customers.
- Team setup:
- Local programmers do front-end in PHP/Rails. They are trying to move over all the front-end to this stack, though some of it is in Java currently.
- Core Tomcat/Java/Spring/Hibernate is coded by a team in Poland. The goal is for Java team to implement the API and backend logic.
- Plan on having a separate database for the PHP/Rails team because they move at much quicker pace than the Java team and they want to uncouple the teams as much as possible so they are not dependent on each other.
- Ran a reliability survey and found most of their outages were due to:
- Network connection problems. They are moving to new datacenter to fix this issue.
- Database overload. To fix this:
- The database contains about 100 tables. The User table has about 100 parameters, which includes information like encoding preferences. The schema still has legacy structure from when the site was hosted on Word Perfect.
- Triple database capacity.
- Use servers that are much faster and have more memory.
- Using a dual-master setup and 4 read slaves.
- Two read slaves will have a low query timeout for interactive traffic.
- Two slaves will be dedicated to reporting and will have long query timeouts. A slow report query will not take the site down with this approach. Their top queries are working on tables that have 10 million rows so calculating top videos takes a much longer amount of time than it used to because it started creating temp tables. Can cause the system to go down for 5 seconds.
- They are investigating running their own CDN using Squid inside their own colos.
- Maybe using a westcoast and eastcoast colos to have geographically distributed peers.
- For their customer they project they would need 4 sites in the US and one in Europe.
- EdgeCast gives them a good deal and provides them useful features like stats per CNAME, but on a profit basis building their own CDN would be worth the development effort. CDN costs are a substantial part of their cost structure and it would be worth squeezing that out over time.
- The future: Long term goal is to see how much money can be saved by getting out of Amazon, running storage locally, running OpenStack, and running their own CDN. That would save 80% of their non-people related operating expenses. From their own calculations they can do it way cheaper than Amazon.
Lessons Learned
- Mix and Match. They are using a combination of nodes from different providers. The CDN handles the content. Amazon is used for stateless operations like encoding and storage. Nodes in the colo are used for everything else. It may be a bit confusing having functionality in several different locations, but they are staying with what works unless there's a compelling business reason or ease of use reason to change. Moving everything to Amazon might make sense, but it also would take them away from their priorities, it would be risky, and it would cost more.
- Watch out for table growth. Queries that used to take a reasonable amount of time can suddenly crush a site once it grows larger. Use reporting instances to offload reporting traffic from interactive traffic. And don't write queries that suck.
- Look at costs. Balancing costs is a big part of their decision making process. They prefer growth via new features over consolidation of existing features. It's a tough balancing act, but consciously making this a strategic imperative helps everyone know where you are going. In the longer term they are thinking about how they can get the benefits of the cloud operations model while taking advantage of the lower cost structure of their own colo.
- Experiment. Viddler loves to experiment. They'll try different technologies to see what works and then actually make use of them in production. This gives them an opportunity to see if new technologies can help them bring down their costs and provide new customer features.
- Segment teams by technology stack and release flexibility. Having distributed teams can be a problem. Having distributed teams on different technology stacks and radically different release cycles is a big problem. Having distributed teams with strong dependencies and cross functional responsibilities is a huge problem. If you have to be in this situation then moving to a model with as few dependencies between the groups is a good compromise.
- Learn from outages. Do a survey of why your site went down and see what you can do to fix the top problems. Seems obvious, but it isn't done enough.
- Use free users as guinea pigs. Free users have a lower SLA expectation so they are candidates for new infrastructure experiments. Having a free tier is useful for just this purpose, to try out new features without doing great harm.
- Pay more for top tier hosting. The biggest problem they've had is picking good datacenters. Their first and second datacenters had problems. Being a scrappy startup they looked for the cheapest yet highest quality datacenter they could find. It turns out datacenter quality is hard to judge. They went with a top name facility and got a great price. This worked fine for months and then problems started happening. Power outages, network outages, and they eventually were forced to move to another provider because the one they were with was pulling out of the facility. Being down for any length of time is not acceptable today and a redundant site would have been a lot of effort for such a small group. Paying more for a higher quality datacenter would have cost less in the long run.
- What matters in the end is what the users sees, not the architecture. Iterate and focus on customer experience above all else. Customer service is even valued above sane or maintainable architecture. Build only what is needed. They could not have kick started this company maintaining 100% employee ownership without running ultra scrappy. They are now taking what was learned in scrappy stage and building a very resilient multi-site architecture in a top-tier facility. Their system is not the most efficient, or the prettiest, the path they took is the customer needs something so they built it. They go after what the customer needs. The way they went about selecting hardware, and building software, with an emphasis on getting the job done, is what built the company.
- Automate. While all the experimentation and solve the immediate problem for the customer stuff is nice, you still need an automated environment so you can reproduce builds, test software, and provide a consistent and stable development environment. Automate from the start.
I'd really like to thank Todd Troxell for taking the time for this interview.
And remember kids, if you are looking for work, Viddler is looking for you too.
Related Articles
- We CAN handle your traffic! by Colin Devroe




{kind=link}